Find the Hidden Network Issues Slowing Down Your AI Workloads
Virtana connects network behavior to AI performance—so you can detect congestion, fix failures fast, and keep data flowing across your AI factory.

40% Reduction in Idle GPU Time
Real-time visibility and optimization lowered GPU underutilization across environments.Global FSI Customer
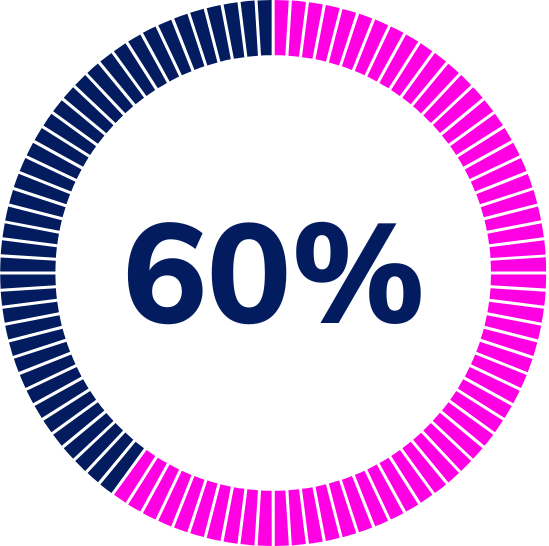
60% Faster Root-Cause Diagnosis
AIFO cut MTTR in half by tracing AI performance issues to infrastructure bottlenecks.Healthcare Provider

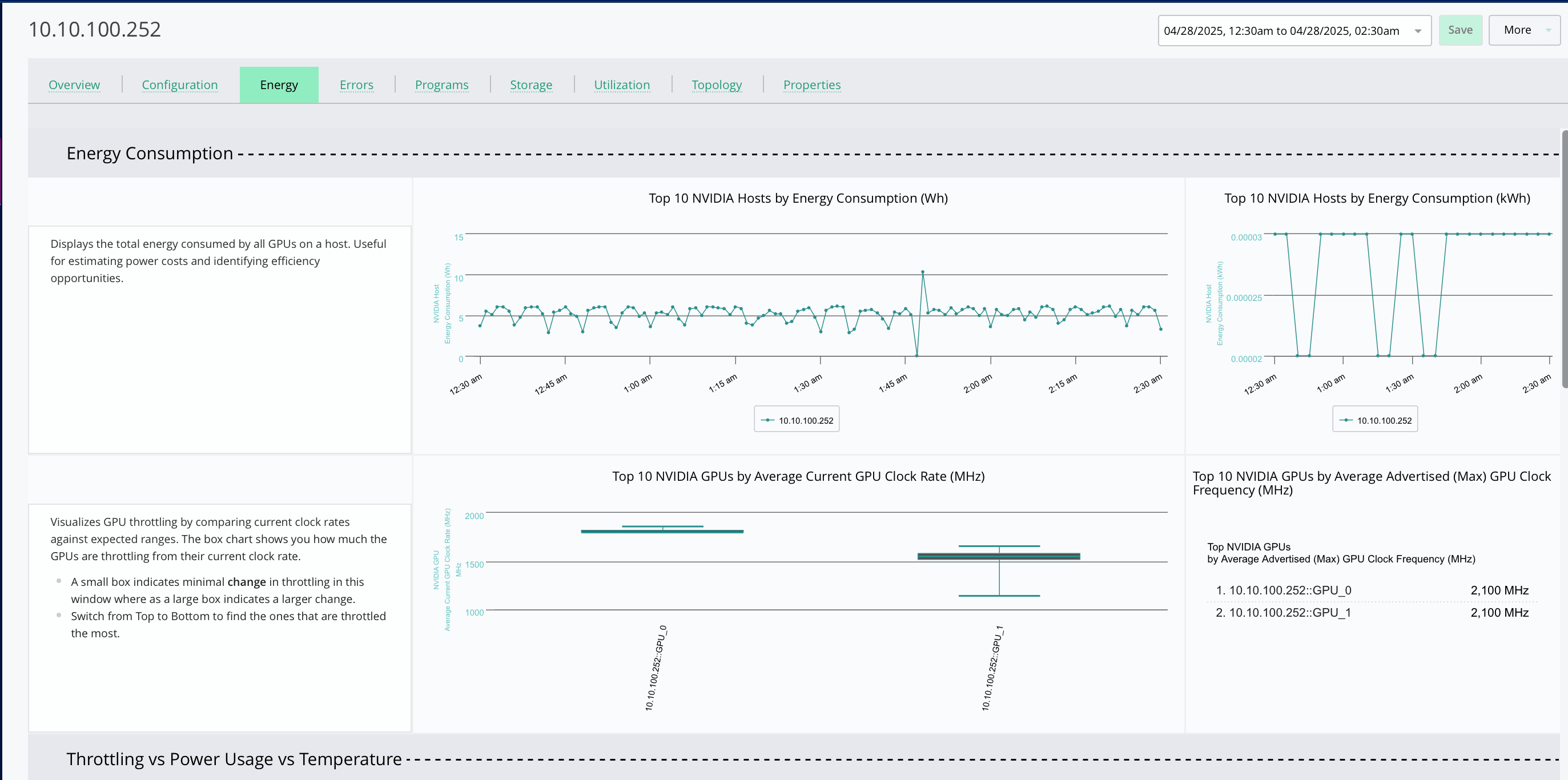
15% Lower Power Usage
Energy analytics revealed throttled GPUs, enabling targeted optimization and cost savings.AI Lab – USA
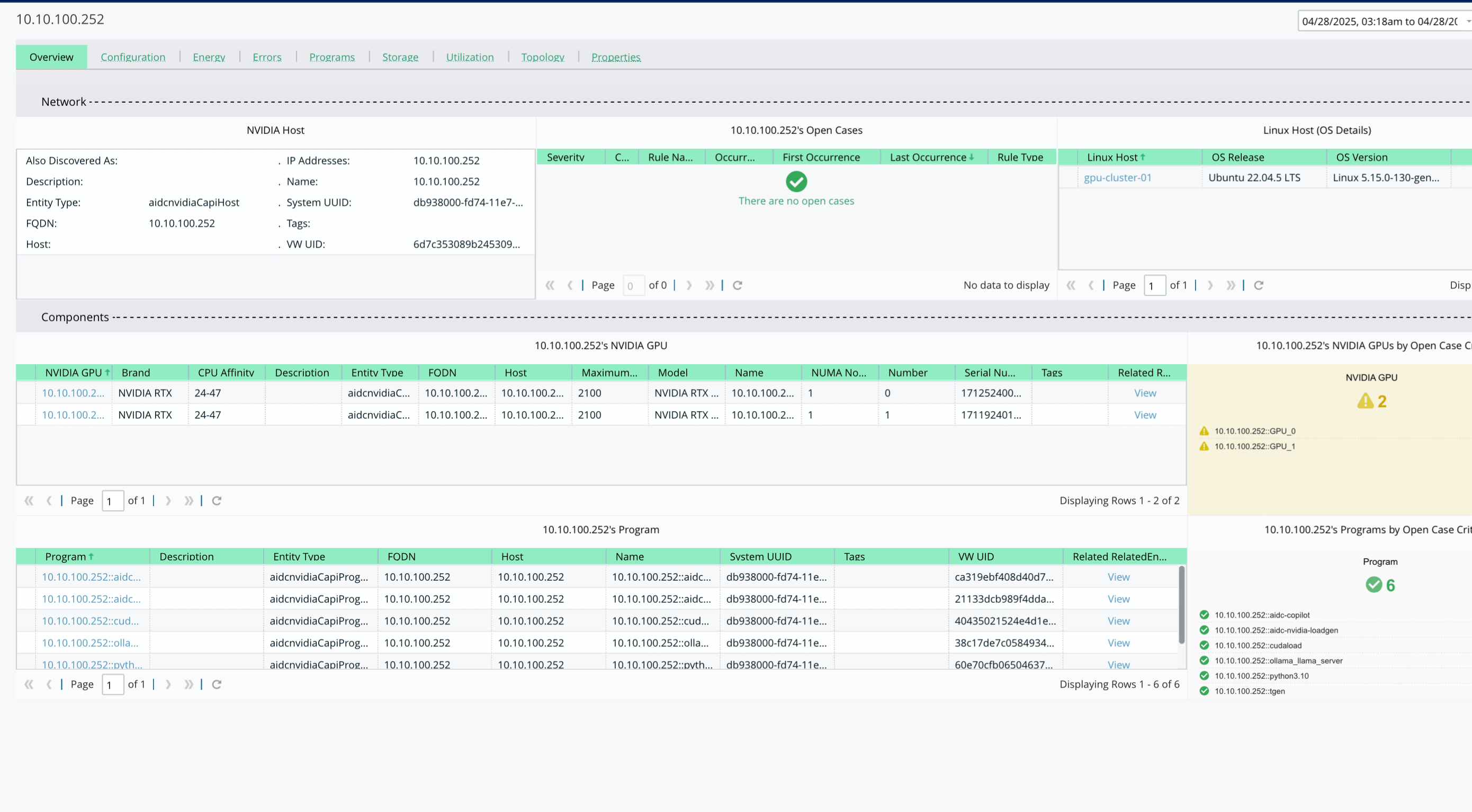
Detect Network Congestion and Misconfigurations
- Monitor bandwidth usage and identify hotspots across your fabric.
- Catch window size mismatches or interface errors that lead to degraded throughput.
- Surface anomalies before they disrupt training or inference pipelines.
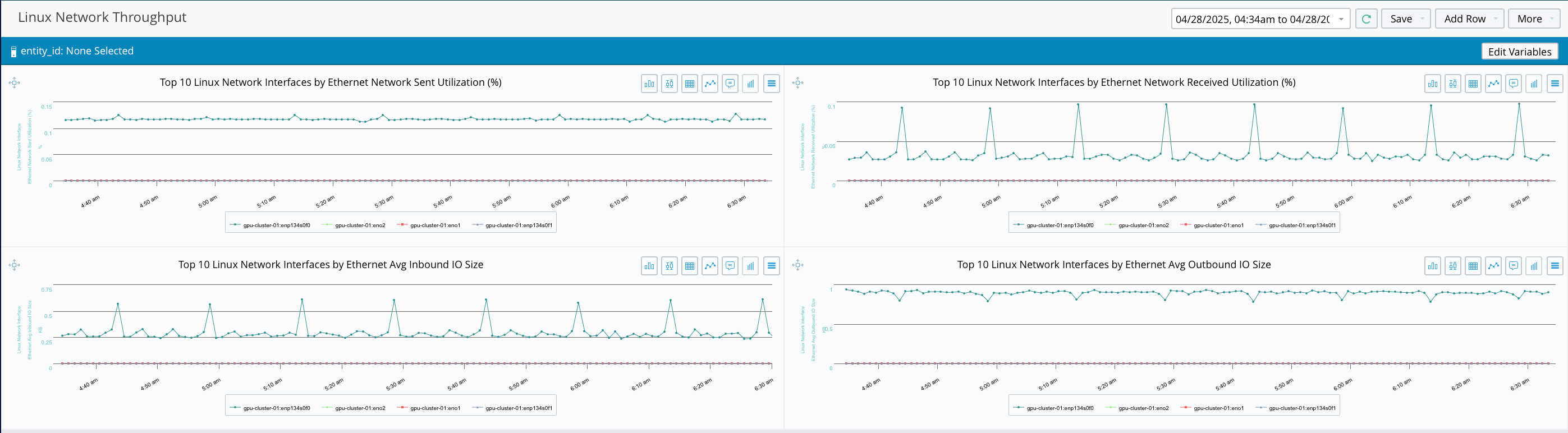
Correlate Network Issues with AI Application Impact
- Use trace correlation to link application slowdowns to specific network events.
- Understand how network latency, dropped packets, or switch port failures affect AI jobs.
- Bridge the gap between SREs and infrastructure teams with shared context.
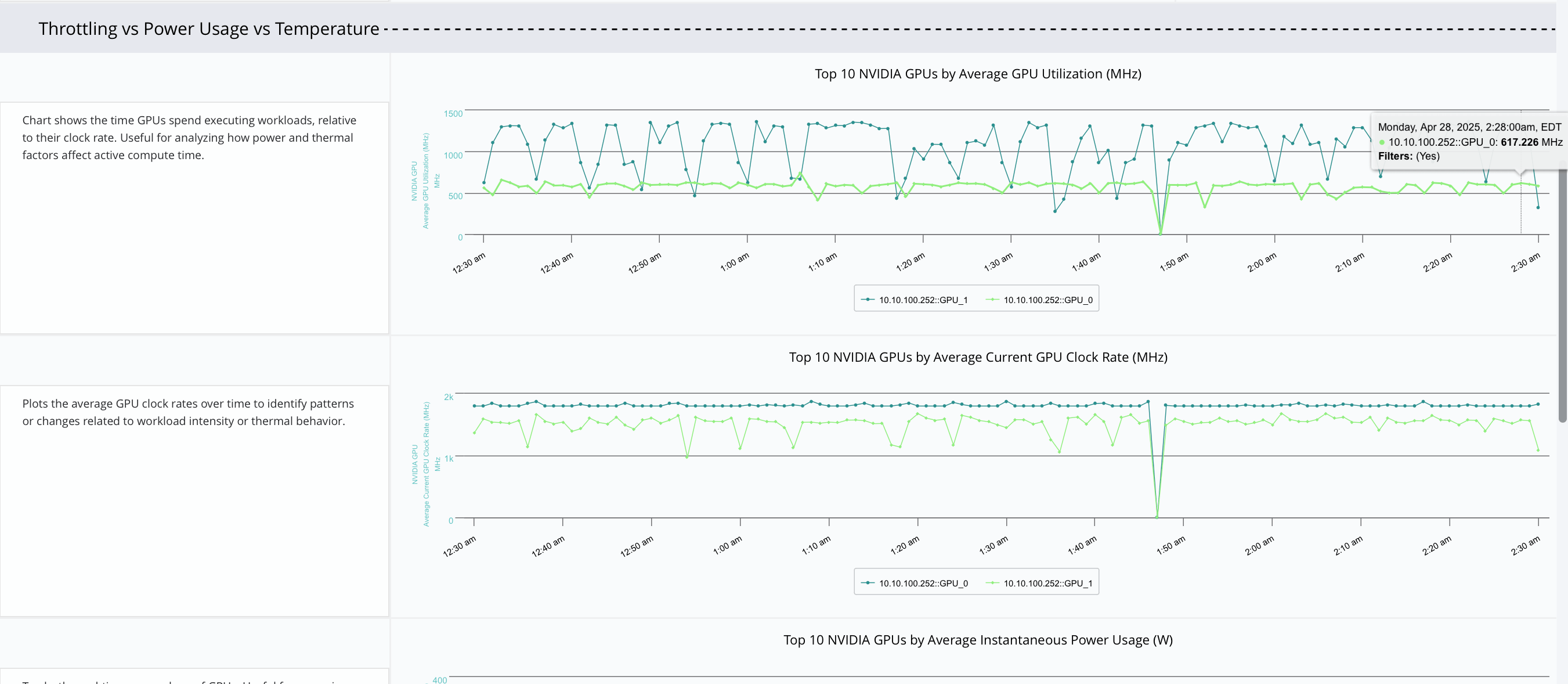
Monitor GPU-to-GPU Network Traffic
- Track data transfers across NVLink/NVSwitch for multi-GPU AI workloads.
- Identify slow interconnects that can bottleneck distributed training performance.
- Get early insight into underperforming or misrouted GPU communication paths.
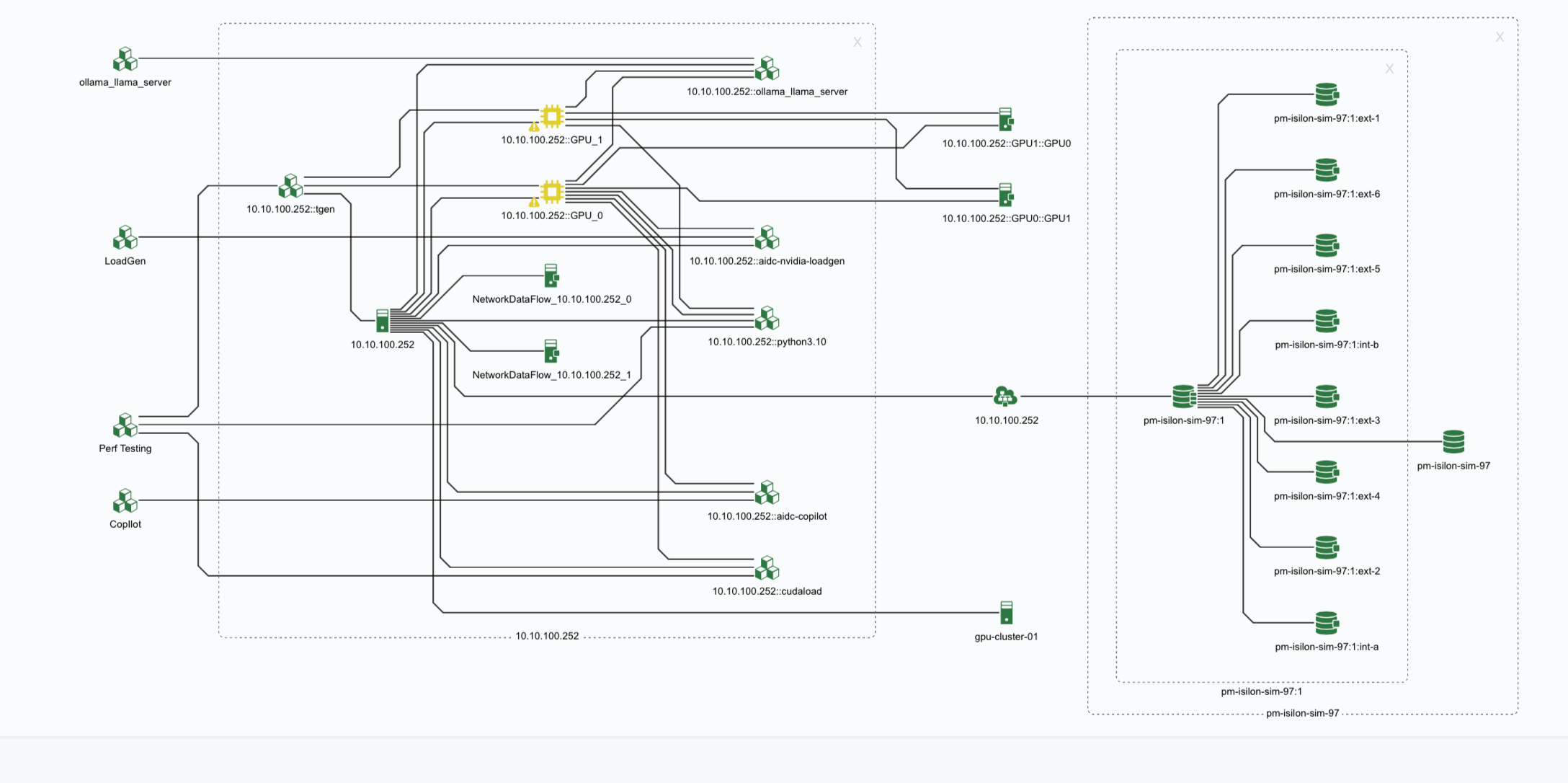
Pinpoint Faults Faster with Root Cause Analytics
- Visualize dependencies between AI services and their underlying network paths.
- Detect failed switch ports or degraded connections in real time.
- Reduce MTTR by going directly to the source of infrastructure-linked failures.
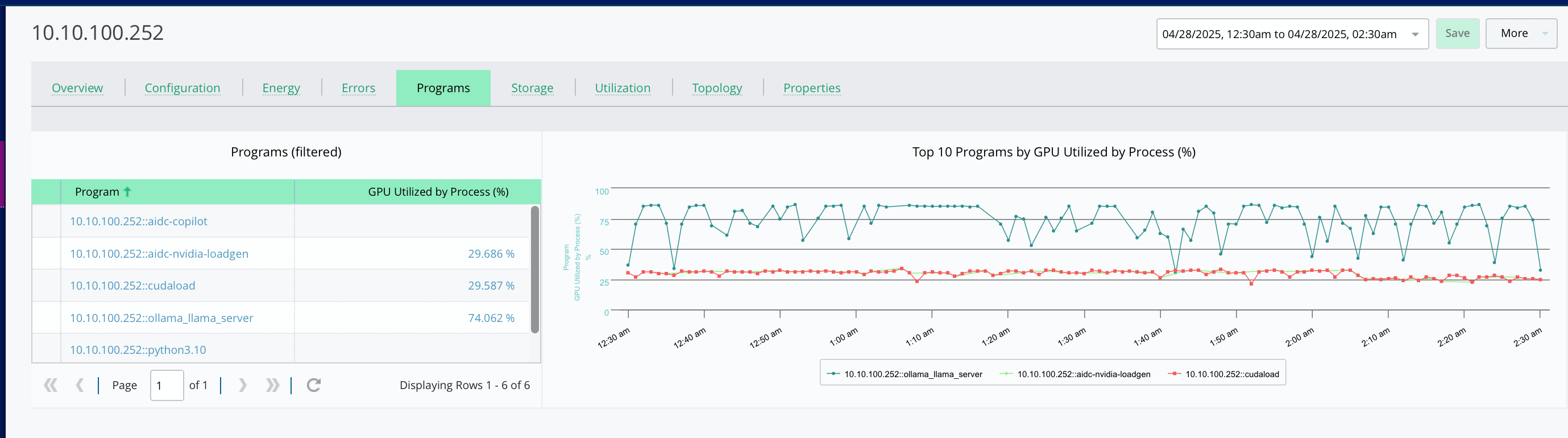
Protect SLA Performance with End-to-End Visibility
- Monitor network health in the context of your AI jobs and services.
- Prioritize fixes based on impact to critical workloads—not just raw metrics.
- Avoid costly interruptions during AI model training by resolving bottlenecks before they escalate.