AI is moving out of the lab and into the heart of the enterprise. But for most organizations, the infrastructure supporting it isn’t ready.
Gartner recently issued a stark warning:
“By 2029, 70% of large enterprises failing to effectively utilize AI factories will cease to exist.”
That’s not a prediction about models or algorithms. It’s a wake-up call about infrastructure.
The risk isn’t just technical. It’s strategic. Without a clear view of how your infrastructure is supporting AI workloads, from GPU utilization and efficiency to data flow to power draw, you’re making high-stakes decisions in the dark. That’s where AI infrastructure observability becomes essential.
What Is an AI Factory?
An AI factory is the full system that transforms raw data into predictions, inferences, or automated decisions. It includes physical infrastructure, orchestration systems, and governance layers that keep everything running in sync.
Think of it like a production line. Raw materials go in. High-value outputs come out. But only if everything in between is visible, reliable, and efficient.
Gartner defines the three layers of an AI factory:
- Physical Infrastructure: GPUs, accelerators, storage, power, and cooling
- Platform Orchestration: Kubernetes, job scheduling, container management
- Governance and Control: Cost tracking, workload policies, performance monitoring
Most enterprises monitor these layers separately, if at all. However, as workloads grow more complex, observability across the entire AI infrastructure is the only way to prevent failure, contain costs, and scale with confidence.
Three Strategic Risks Gartner Identifies
1. Power and Cooling Will Eclipse Hardware Spend
Gartner, enterprises will spend more on powering and cooling AI hardware than they do projects that by 2027buying it.
If your team can’t measure or control energy consumption by workload, this shift will hit your budget and sustainability goals hard. AI infrastructure observability allows you to monitor power draw in real time and optimize workloads accordingly.
2. Fragmented Tools Hide Critical Failures
Gartner highlights the complexity of current AI operations. Monitoring is siloed across teams and tools, with GPU dashboards here, job logs there, cost analytics somewhere else.
When something breaks or slows down, root cause analysis takes too long. Without unified observability, AI systems stay fragile, even when they’re technically online.
3. Capital Investment Without Insight Is a Risk Multiplier
Gartner recommends validating AI workloads in the cloud before investing in large capital deployments. But to validate, you need visibility into performance, utilization, efficiency, and resource contention.
AI infrastructure observability enables teams to test, benchmark, and plan before scaling up infrastructure spend.
The Winners Are Already Operating Differently
“By 2029, the top 25% of enterprises that master AI factories will control 75% of their respective markets.” – Gartner
What sets these companies apart isn’t just their data science talent or GPU count. It’s how they operate their AI infrastructure.
- They trace inference issues back to orchestration and node-level performance
- They monitor job efficiency, power usage, and cooling in real time
- They use observability to reduce cost, increase output, and meet SLAs consistently
In short, they treat infrastructure observability as a strategic capability—not a technical afterthought.
Six Questions to Pressure-Test Your AI Infrastructure
If you’re responsible for running AI workloads, it’s not enough to measure uptime. You need to understand what’s really happening under the surface. Take a moment to assess your current environment. Can you answer yes to the following?
1. Can your team trace slowdowns or failures across all infrastructure layers?
When a training job stalls or inference latency spikes, the root cause could be in the model, or in storage, network, or power. Without the ability to trace issues from application to infrastructure, every problem becomes a guessing game.
2. Do you know how much GPU capacity is actually being used vs. overprovisioned?
It’s common to buy more GPUs when performance lags. However, utilization hovers below 60% in many environments due to scheduling inefficiencies or idle time. Visibility into actual usage prevents overprovisioning and reveals where you can reclaim capacity.
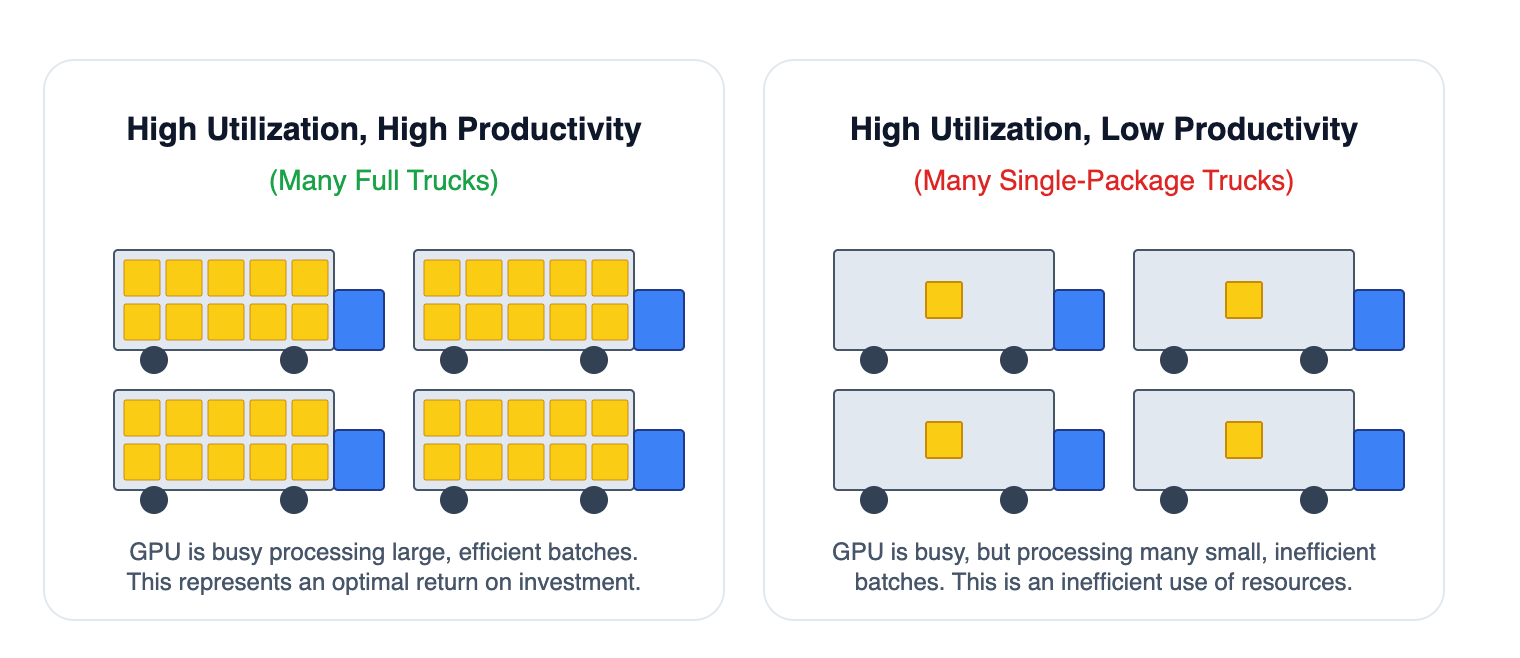
3. Do you know the difference between GPU utilization and GPU efficiency, and can you measure both?
A GPU at 90% utilization may look busy, but that doesn’t mean it’s doing productive work. Memory bottlenecks, inefficient job code, or thermal throttling can all result in high usage but low output. Observability helps teams distinguish raw utilization from meaningful efficiency—so you’re not just busy, you’re optimized.
4. Can you track energy consumption and correlate it with workload performance?
AI workloads consume enormous power. But without workload-level telemetry, it’s hard to optimize placement or manage costs. Observability lets you align performance with power draw, so you can run efficiently, not just powerfully.
5. Are silent failures or straggler nodes detectable before impacting SLAs?
Distributed AI jobs can fail silently or degrade slowly when one node falls behind. By the time symptoms show up, it’s often too late. Real-time detection of outliers, lag, or node drift is essential for meeting SLAs and maintaining throughput.
6. Can you scale AI workloads without losing control of cost or performance?
What works for a pilot often breaks at scale. Without observability, teams hit a wall, unable to spot resource contention, optimize orchestration, or prevent cascading failures. Scaling AI requires more than hardware. It requires operational clarity.
If the answer to any of these is no, you likely have gaps in your observability stack and risk falling into the 70% Gartner warns about.
Where to Go From Here
AI infrastructure observability is not a luxury. It’s how organizations turn complex AI operations into resilient, scalable, and cost-effective systems.
The companies that win in AI aren’t just building better models. They’re building more intelligent factories with infrastructure they can see, understand, and control.
If you’re ready to map your blind spots and build visibility into every layer of your AI factory, schedule a 20-minute consult with our team. We’ll help you identify performance risks, uncover hidden waste, and explore practical steps for scaling AI infrastructure the right way.
You don’t need more hype. You also don’t need to throw more expensive hardware at the issue. You need clarity.
Citation:
Gartner, “Innovation Insight for GenAI Infrastructure” Chirag Dekate, Sushovan Mukhopadhyay, July 10, 2025. ID G00828480.

James Harper
Head of Product Marketing, Virtana