“Monitoring, by definition, suggests that you know what you are looking for.” This seemingly simple statement encapsulates one of the most significant challenges facing IT organizations today. In traditional monitoring approaches, we focus on tracking “known knowns” and “known unknowns.” But what happens when you don’t know what you’re looking for?
The answer lies in observability—a concept that has changed how organizations operating hybrid environments approach IT operations. According to Gartner’s 2024 report, “The term ‘observability,’ borrowed from control theory, has entered the IT monitoring lexicon to describe a holistic, data-centric approach that emphasizes an exploratory capability and enables the identification of ‘unknown unknowns.'” This shift is far more than a terminology change, it’s an evolution in how we understand and manage modern IT environments.
Why Traditional Monitoring Falls Short
Modern distributed systems, especially those where services are created and supported by multiple teams, create unprecedented complexity. In these environments, it becomes virtually impossible to understand the complete details of an application’s internal state at any given time, or to ensure consistent performance for all users.
Traditional monitoring approaches were designed for more predictable, monolithic applications where:
- System components and interactions were relatively stable.
- Failure modes were largely understood in advance.
- Teams could predict most of what might go wrong.
As applications have evolved into complex microservices architectures deployed across hybrid and multi-cloud environments, monitoring alone simply cannot keep pace. The number of potential failure modes has expanded exponentially, and the dynamic nature of these environments means that yesterday’s monitoring configuration may be irrelevant today.
Monitoring vs. Observability: Understanding the Key Differences
To appreciate the power of observability, it’s essential to understand how it differs from traditional monitoring:
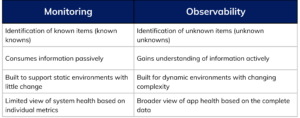
Perhaps the simplest way to understand the distinction: “Monitoring is what tells you something is wrong, while observability gives you the information to help you fix it.”
Monitoring approaches generally ask questions based on pre-built dashboards, while observability encourages active exploration based on hypotheses. This fundamental difference in approach enables teams to tackle problems they didn’t predict when setting up their monitoring systems.
What is an Observability Platform?
An observability platform serves as the foundation for understanding the health, performance, and behavior of modern applications and infrastructure. It provides answers to the critical question: “How do I ensure that the health and performance of my infrastructure and application services meet my organization’s objectives?”
Specifically, an observability platform:
- Ingests operational data from a variety of sources.
- Analyzes application, service, and infrastructure behavior.
- Shows changes in system behavior that impact end-users.
- Enables early and preemptive problem remediation.
Unlike traditional monitoring tools, observability platforms are designed for multiple stakeholders within an organization, including IT operations teams, site reliability engineers, cloud and platform teams, application developers, and product owners—each bringing unique perspectives and requirements.
Core Characteristics of Observability Platforms
Effective observability platforms deliver capabilities across three primary dimensions:
Ingest
They ingest, store, and analyze operational telemetry feeds, including (but not limited to) metrics, events, logs, and trace data from across the technology stack.
Analyze
They find and analyze changes in application, service, or infrastructure behavior to find availability outages, performance degradation, and impact on end-user experience.
Enrich
They provide contextualization through topological dependency mapping and showing relationships between technical components and business services.
The most sophisticated observability platforms also deliver the following:
- Interactive exploration and analysis of multiple telemetry types.
- AI/ML-powered insights that would be impossible to derive manually.
- Automated discovery and mapping of infrastructure, network, and application components
- Cost management capabilities for optimizing application workload costs and platform utilization.
Practical Applications of Observability
Observability transforms how organizations approach problem-solving in complex environments:
Proactive Issue Detection
Rather than waiting for an alert to fire when a threshold is breached, observability enables teams to identify emerging issues before they impact users. By analyzing patterns and trends across multiple data sources, observability platforms can detect subtle changes in system behavior that might show an impending problem.
Complex Root Cause Analysis
When issues do occur, observability provides the context needed to understand the root cause. For example: is performance degradation due to a code change, increased load, infrastructure issues, or a combination of factors? Observability platforms help teams navigate these complex investigations by connecting seemingly disparate data points.
Service Impact Assessment
Observability helps organizations understand the business impact of technical issues by mapping dependencies between services and establishing their relationship to business-critical functions. This enables more informed prioritization and better communication with business stakeholders.
Performance Optimization
Beyond troubleshooting, observability provides insights that help teams optimize their applications and infrastructure. By understanding how different components interact and contribute to overall performance, teams can make targeted improvements that deliver significant business value.
The Evolution from Monitoring to Observability
The transition from monitoring to observability isn’t about replacing existing tools but rather expanding capabilities to meet modern challenges. Most organizations will keep elements of both approaches:
- Monitoring stays valuable for tracking well-understood metrics and generating alerts when key thresholds are crossed.
- Observability extends these capabilities by providing the context and tools needed to understand complex, dynamic systems.
Organizations typically evolve their approach by:
- Enhancing existing monitoring with expanded data collection
- Implementing tools that enable correlation across different data types.
- Developing topology mapping to understand dependencies
- Adopting advanced analytics to identify emerging issues
- Building cross-functional processes that use observability data.
This evolution doesn’t happen overnight, but each step delivers incremental value and prepares organizations for the increasingly complex IT landscapes they must manage.
Virtana Platform: The Deepest and Broadest Hybrid Observability Platform
Virtana Platform exemplifies the observability approach by delivering all the core characteristics that define modern observability platforms:
- Centralized Alerts Dashboard: Reduces noise and enriches insights with policy-based notifications.
- Comprehensive Topology: Deep discovery and mapping of IT architecture elements, inclusive of storage, compute, network, and data fabric.
- Automated Notification & Remediation: Integrates with ServiceNow, Slack, email, and more for seamless issue management.
- Root Cause Analysis & Self-Healing: Rapidly identifies and resolves issues, minimizing downtime.
- Hybrid Cost & Capacity Management: AI-driven recommendations for optimization across hybrid environments.
- Virtana Copilot: An intuitive, natural language interface for querying infrastructure unknowns.
- Multi-Environment Flexibility: Observe and deploy across on-premises, colocation, and cloud environments.
Unlike traditional monitoring tools that focus on predefined metrics, Virtana Platform enables teams to actively explore and understand their environments, find emerging issues, and connect technical performance to business outcomes.
Conclusion
As IT environments continue to grow in complexity, the limitations of traditional monitoring approaches become increasingly clear. Observability is not just a new set of tools but a fundamental shift in how organizations understand and manage their technology stacks.
By enabling the identification of “unknown unknowns,” observability platforms like Virtana empower teams to navigate complexity with confidence, resolve issues more quickly, and ensure that applications perform optimally for all users.
The future belongs to organizations that can not only detect when something is wrong but quickly understand why it’s happening and how to fix it. That’s the power of observability.
Next Steps
Ready to move beyond basic monitoring? Learn how Virtana’s observability platform can help your organization navigate complexity and ensure optimal performance of your critical applications. Contact us today for a personalized demo.

David McNerney
David McNerney is Director of Product Management at Virtana, leading Application Observability, Container Observability, and Service Observability. He focuses on building the cloud and hybrid monitoring capabilities that enable Global 2000 enterprises to resolve incidents faster and optimize infrastructure costs.


