The promise of AI has never been bigger. From generative AI assistants transforming customer service to large language models (LLMs) powering research, coding, and content creation, organizations across industries are racing to integrate AI into real-world workflows. The hype is everywhere: bold claims about disruption, efficiency gains, and billions in potential business value.
But here’s the hard truth: AI projects rarely deliver on their promise once they move from lab experiments to production environments. Deploying an AI agent is not the end of the journey—it’s the beginning of a much more complex phase. In fact, how you manage your models after deployment often determines whether your initiative succeeds or fails.
The Harsh Reality: AI Failure Rates Are Shockingly High
Recent industry research shows just how fragile AI projects can be when pushed into the real world:
- Gartner predicts that over 40% of agentic AI projects will be scrapped by 2027, primarily because costs spiral out of control and business impact is unclear (Reuters).
- S&P Global reports that 42% of companies abandoned most of their AI initiatives in 2025, up sharply from just 17% in 2024. On average, organizations scrapped nearly half of their AI proof-of-concepts before production (Cybersecurity Dive).
- RAND Corporation found that more than 80% of AI projects fail, which is twice the failure rate of non-AI technology projects (RAND).
- Per Forbes, citing Gartner, 85% of AI models fail due to poor or insufficient data quality (Forbes).
These statistics underline a sobering point: the biggest challenges for AI don’t show up in proof-of-concepts or demos—they appear in production, under real workloads, with real costs, and real user expectations.
Why Observability Matters from Day One
AI models in production are living systems. Their performance isn’t static—it changes with user demand, evolving data, infrastructure fluctuations, and orchestration complexity. What worked flawlessly in a test environment often struggles under the unpredictable conditions of the real world.
That’s why observability is critical. Observability means having the tools and insights to:
- Detect when performance begins to degrade.
- Understand whether issues originate from the model, orchestration, or infrastructure.
- Track how costs evolve alongside usage.
- Optimize capacity so you’re not overspending or under-serving users.
Think of AI in production like Formula 1 racing. The car (AI model) may be engineered to perfection, but without constant monitoring of tires, fuel, aerodynamics, and telemetry, even the best driver won’t win. Observability is your race engineer—keeping your AI system running at peak performance while avoiding costly breakdowns.
Where AI Projects Break Down: Model, Orchestration, or Infrastructure
When problems appear in production, they often surface as latency spikes, increasing error rates, or unexpected costs. But where exactly is the failure? It could be in one of three places:
- AI Model/Application Layer – The model itself could be inefficient, poorly tuned, or generating excessive token usage that drives costs through the roof. Output quality may degrade if the data shifts, leaving users dissatisfied.
- Orchestration Layer – Complex environments like Kubernetes may cause scheduling delays, pod failures, or scaling mismatches. If orchestration isn’t optimized, workloads don’t get the resources they need at the right time.
- Infrastructure Layer – GPUs are high-value assets, but without visibility, they may be underutilized or overloaded. Bottlenecks in memory or interconnect bandwidth can silently throttle performance, while costs continue to rise.
The challenge is that these layers are interconnected. A latency issue might look like a model problem, but actually stems from GPU memory saturation. Or costs might spike not because of token usage but due to poor orchestration scaling.
Traditional monitoring tools look at one layer in isolation, leaving teams guessing. What enterprises need is full-stack observability that spans across the model, orchestration, and infrastructure layers and ties them together into a single view.
Why Virtana Is Your Best Partner for AI Observability
Virtana is purpose-built to address these challenges. It helps enterprises move beyond “AI hype” to “AI at scale” by ensuring their models perform reliably, efficiently, and cost-effectively. Here’s why organizations trust Virtana.
1. Full-Stack Observability: Application → Orchestration → GPU Infrastructure
Virtana doesn’t stop at application metrics. It provides a unified view across the full stack:
- Application layer: Monitor model throughput, latency, token usage, and errors.
- Orchestration layer: Visualize Kubernetes, Docker, and other systems to identify inefficiencies and bottlenecks.
- Infrastructure layer: Track GPU utilization, memory, and interconnect performance to ensure your expensive hardware is being fully optimized.
With this full-stack perspective, teams can do root cause analysis in minutes instead of days, reducing downtime and keeping AI services reliable.
2. Flexible Deployment: On-Premises, Cloud, or Hybrid
AI workloads live everywhere—sometimes on-premises for compliance, sometimes in the cloud for scale, and increasingly in hybrid environments. Many enterprises juggle multiple environments at once.
Virtana supports all deployment models:
- On-prem for sensitive workloads.
- Cloud for elasticity and fast scaling.
- Hybrid for real-world enterprise complexity.
This means you get consistent observability no matter where your AI runs. No blind spots, no fragmented monitoring.
3. Cost and Capacity Efficiency for AI / LLM Models
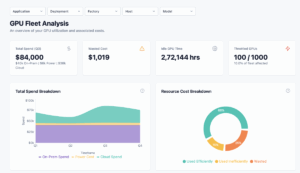
AI may deliver innovation, but it also comes with massive bills. GPUs are expensive, cloud compute costs scale unpredictably, and token-based pricing models can quickly spiral.
Virtana provides deep insights into costs and capacity:
- Track token usage and translate it into dollar impact.
- Monitor cloud and GPU spend, identifying opportunities to consolidate or right-size.
- Ensure maximum utilization of hardware—avoiding both underuse (waste) and overuse (performance degradation).
By aligning infrastructure use with business needs, Virtana ensures AI projects remain financially sustainable.
The Business Value of AI Observability
When organizations implement Virtana, they’re not just gaining visibility—they’re gaining business advantage:
- Reliability: Fewer outages and faster recovery when issues arise.
- Performance: Higher throughput and lower latency, keeping users happy.
- Cost Control: Predictable AI spend and maximized ROI from GPU/cloud investments.
- Scalability: Confidence to scale AI adoption without fear of runaway costs.
- Governance: Compliance-ready monitoring across hybrid environments.
This is how enterprises move beyond pilots and proofs-of-concept into sustained, value-driven AI adoption.
Conclusion: The Journey Begins at Deployment
From hype to hard reality, AI projects don’t fail because the models are bad—they fail because operational execution is missing. The moment an AI system is deployed into production is not the finish line; it’s the starting point of a continuous journey of monitoring, optimization, and cost management.
Virtana equips organizations to succeed in this journey. By delivering full-stack observability, flexible deployment, and cost/capacity insights, Virtana ensures your AI initiatives don’t just launch—they thrive, delivering real business value.
In today’s competitive landscape, success in AI won’t be defined by who deploys first. It will be defined by who can operate AI most effectively, at scale, and with efficiency. With Virtana, that can be you.
We invite partners who are ready to begin their AI journey with Virtana. Connect with us to explore partnership opportunities.
Author Bio: Meeta Lalwani is a director of product management professional leading the AI Factory Observability and GenAI Portfolio for Virtana Platform. She is passionate about modern technologies and their potential to positively impact human growth.

Meeta Lalwani
Senior Director – Product Management


