Distributed Tracing
Contextual tracing for monitoring end-to-end business/application transactions, optimizing microservices performance, and troubleshooting performance issues.
Book a Demo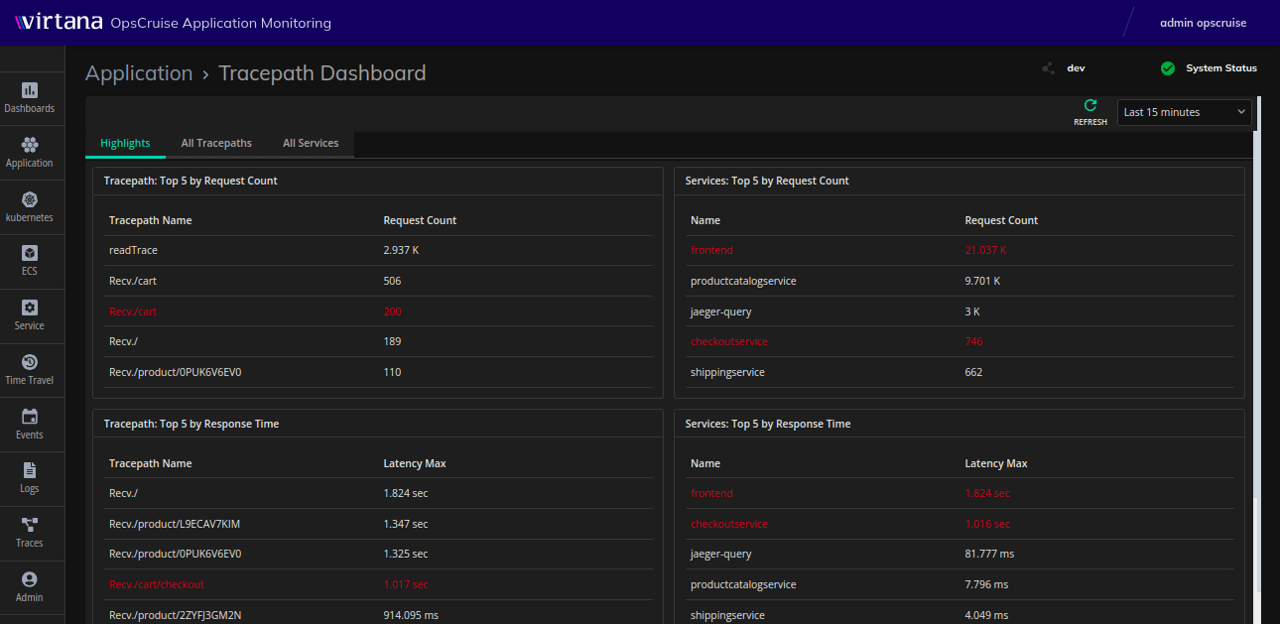
Distributed Tracing That’s Usable in Real Time
Leverages existing CNCF tracing tools—such as Jaeger, OpenTelemetry, and others—to complement Virtana Application Monitoring’s eBPF-based flow analytics application graph.
End-to-End Business-Level Application Performance Monitoring
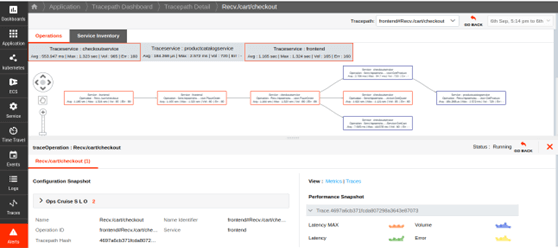
- Follow requests from real user, synthetic, or browser test sessions to services, serverless functions, and databases.
- View traces and logs in context with automatic trace_id injection from Jaeger and other popular open-source tools.
- Connect distributed traces to infrastructure metrics, network calls, and live processes.
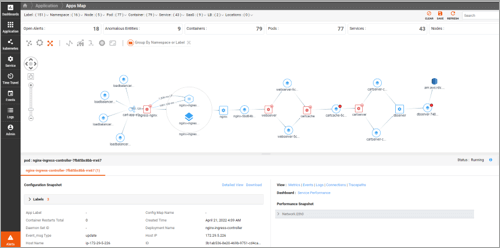
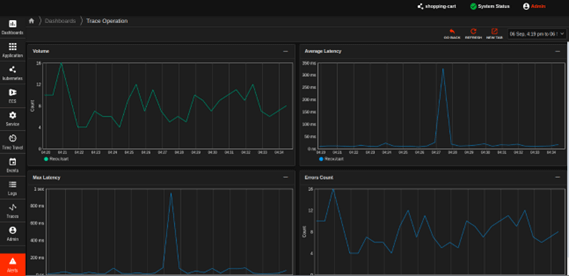
Trace Service Graph
- Capture the execution path of each trace and aggregate them into trace-path signatures.
- Get a real-time view of each trace path’s performance.
- Predictively detect problems in the trace path.
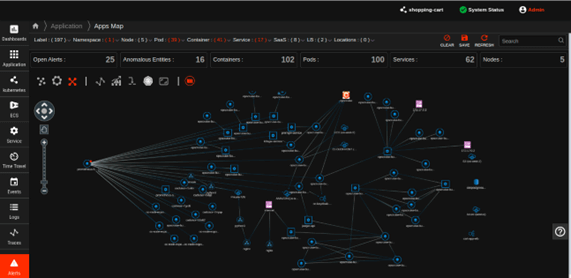
Live Visibility With Complete Control
- Examine all ingested traces and service dependencies over the last 5 minutes.
- Automatically surface error, throughput, and latency outliers during active investigations with anomaly ML-based insights to resolve issues faster.
- Set custom tag-based retention filters to retain only the traces that are most important to your business.
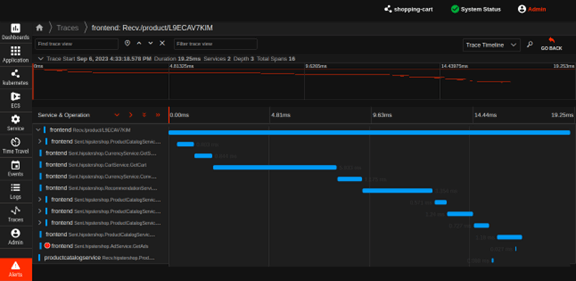
Automated Causal Analysis and Code-Level Insights
- View a breakdown of slow requests by time spent in code on CPU, GC, lock contention, and I/O to minimize service latency.
- Optimize code and save on infrastructure costs with always-on, low-overhead code profiling.
- Monitor profile aggregations of services/endpoints and detect bottlenecks in your code to improve application performance.
- Compare code profiles using any time frame and tag to rationalize performance regressions caused by inefficient code.
Contextual Log Integration
- Integrate contextual logs from various microservices to get a unified view of trace data and corresponding log events.
- Combine trace information with contextual logs to get a comprehensive understanding of the application’s behavior, enabling more efficient root-cause analysis and troubleshooting.
- Use a holistic view of transactions and associated events to reduce time required to identify and resolve issues, reduce downtime, and improve overall application reliability.