Keep AI Training Jobs on Track—From Start to Finish
Virtana helps you monitor, troubleshoot, and optimize long-running training jobs, so you can avoid costly failures, speed up development, and make the most of your infrastructure.

40% Reduction in Idle GPU Time
Real-time visibility and optimization lowered GPU underutilization across environments.Global FSI Customer
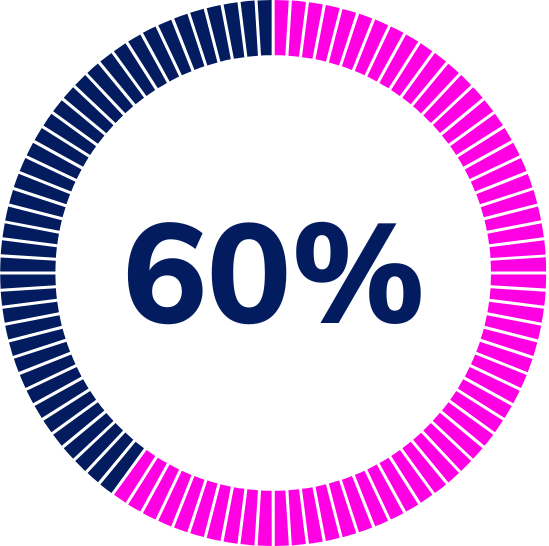
60% Faster Root-Cause Diagnosis
AIFO cut MTTR in half by tracing AI performance issues to infrastructure bottlenecks.Healthcare Provider

15% Lower Power Usage
Energy analytics revealed throttled GPUs, enabling targeted optimization and cost savings.AI Lab – USA
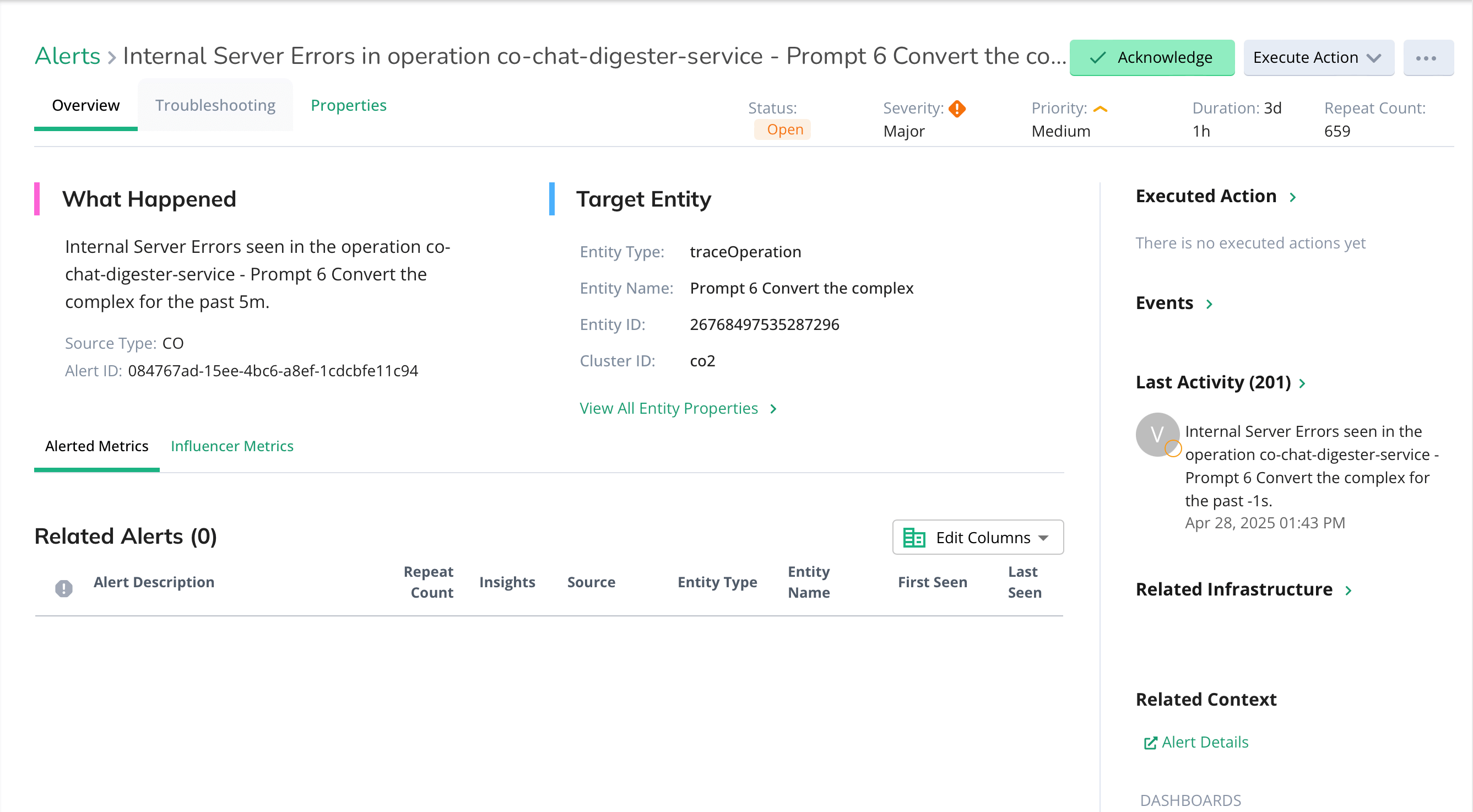
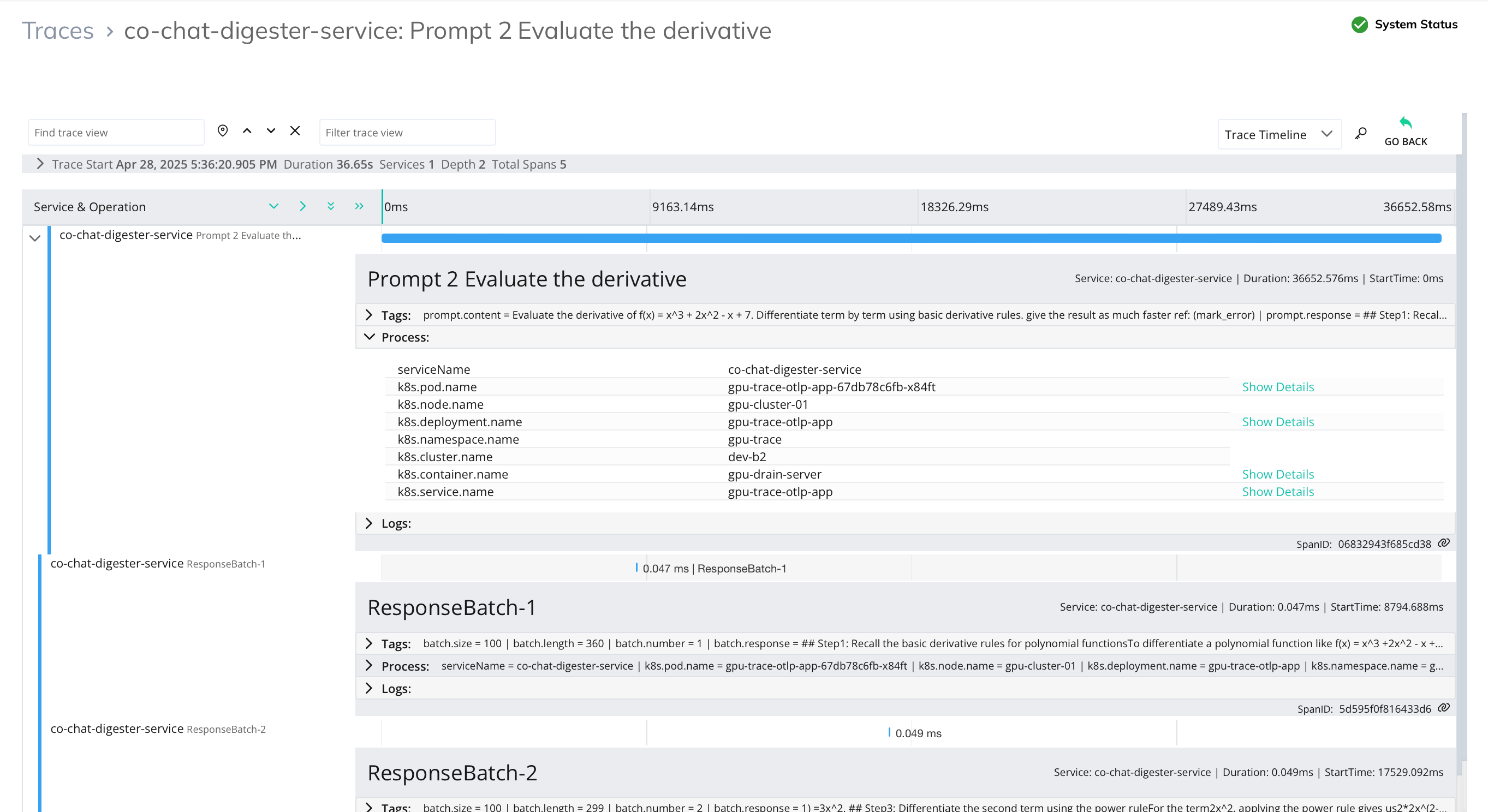
Reduce MTTR for Training Job Failures
- Identify the exact cause of failed training runs, whether it’s a port reset, hardware issue, or network drop.
- Cut debugging time from days to minutes with trace-to-infra correlation.
- Minimize reruns and lost compute hours with fast, accurate root cause insights.
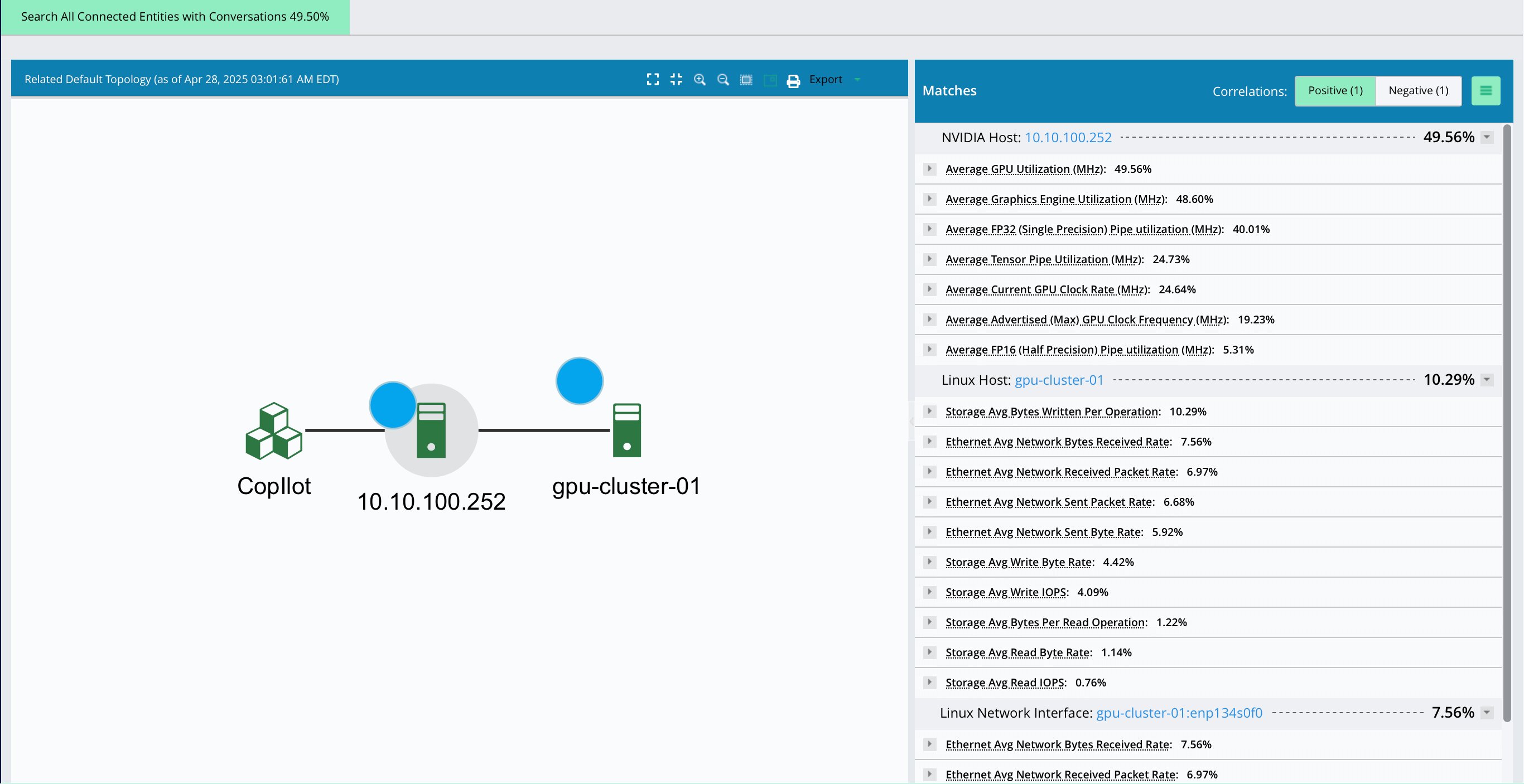
Monitor Long-Running Jobs with Confidence
- Track training workloads that span hours or days with real-time infrastructure telemetry.
- Detect early warning signs of resource contention, thermal issues, or infrastructure instability.
- Avoid silent failures that derail progress or corrupt model outputs.
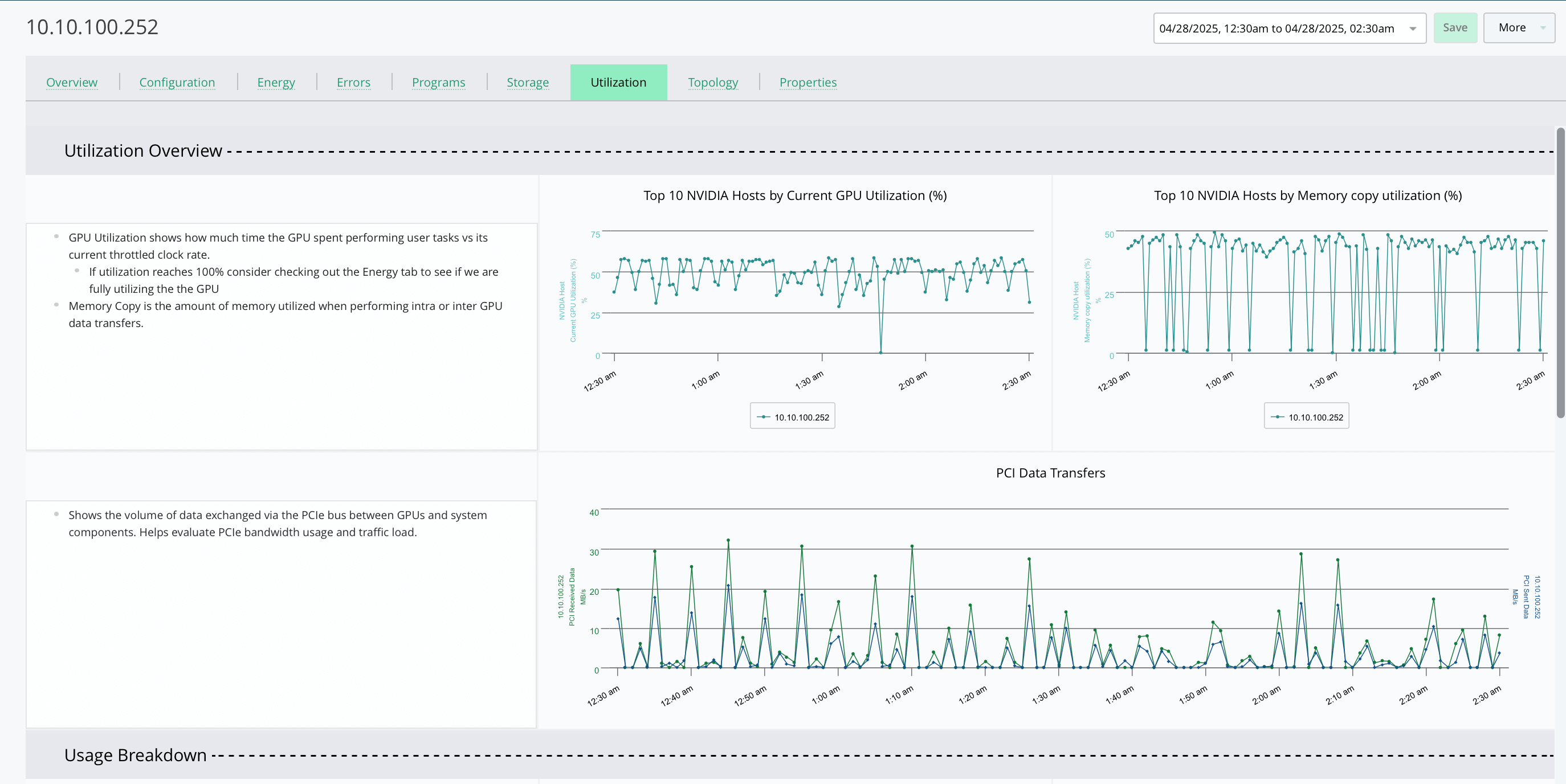
Optimize Infrastructure for Model Throughput
- Analyze how GPU placement, host configuration, and job scheduling affect performance.
- Surface inefficiencies like throttled GPUs or suboptimal interconnect paths.
- Improve utilization and shorten training times by aligning workloads with resource readiness.
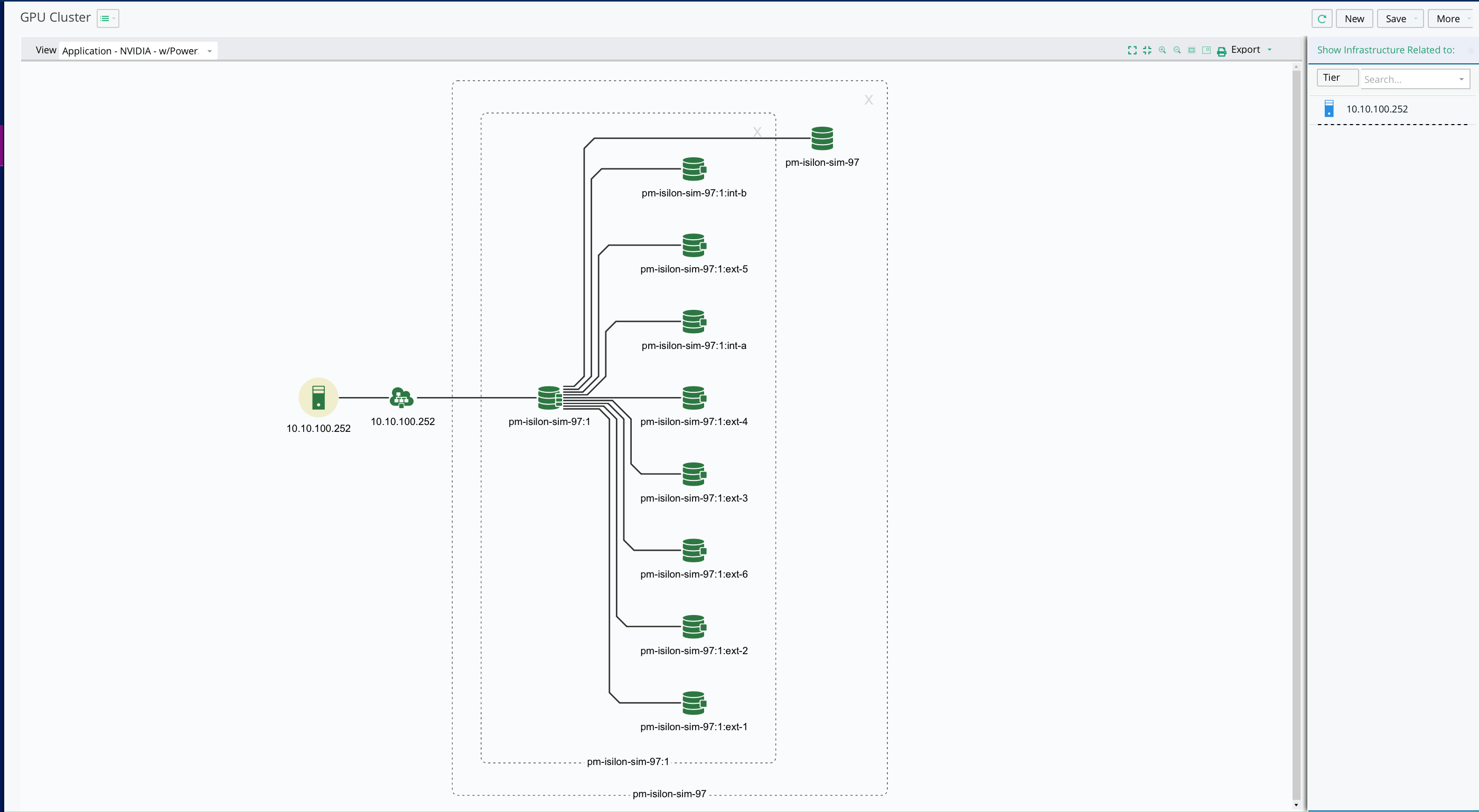
Map Training Jobs to Physical Infrastructure
- See exactly where each training run is executing down to the GPU, host, and network layer.
- Correlate performance dips to backend hardware and environmental factors.
- Enable precise tuning of job placement and infrastructure provisioning.
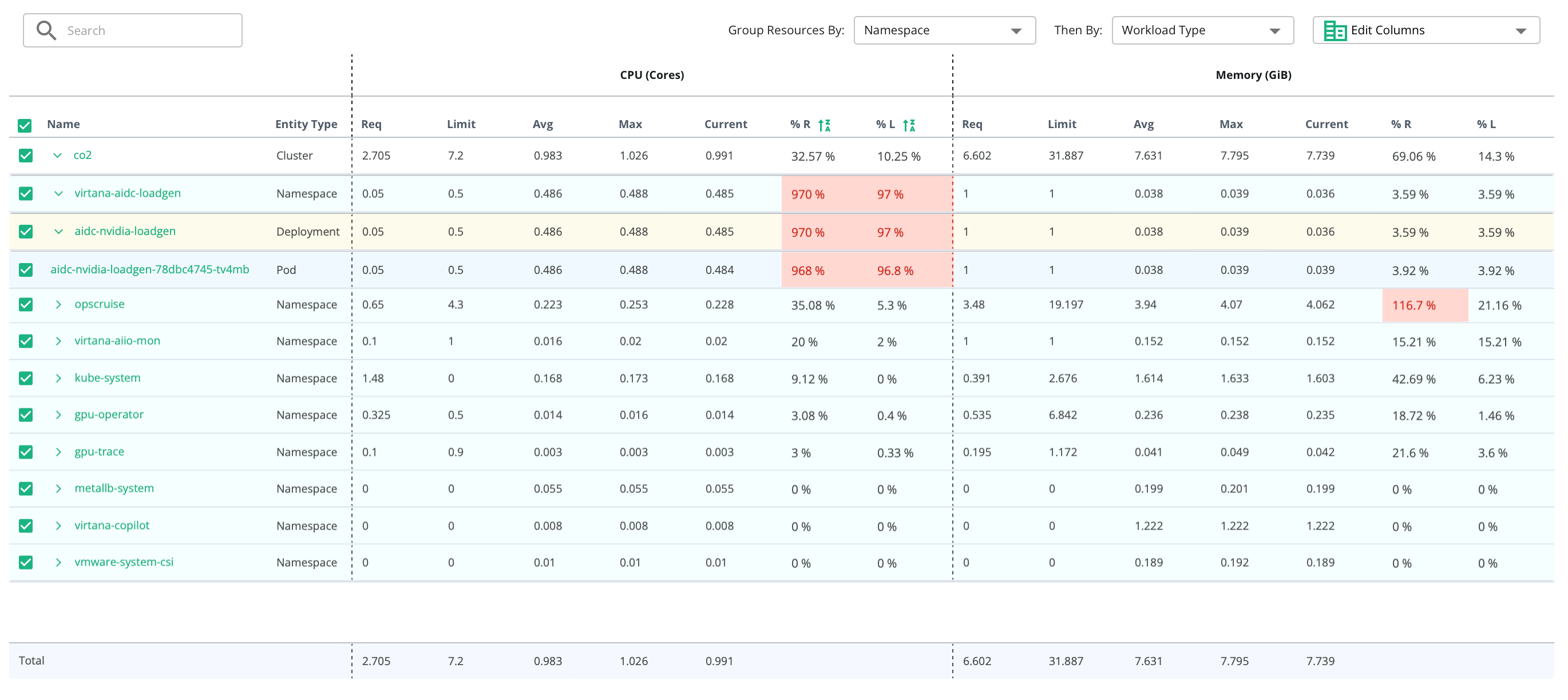
Avoid Overprovisioning and Wasted Spend
- Eliminate idle or underused infrastructure by aligning resource capacity to job demand.
- Identify where you’re paying for performance you’re not getting.
- Reclaim budget by right-sizing compute environments for AI training.