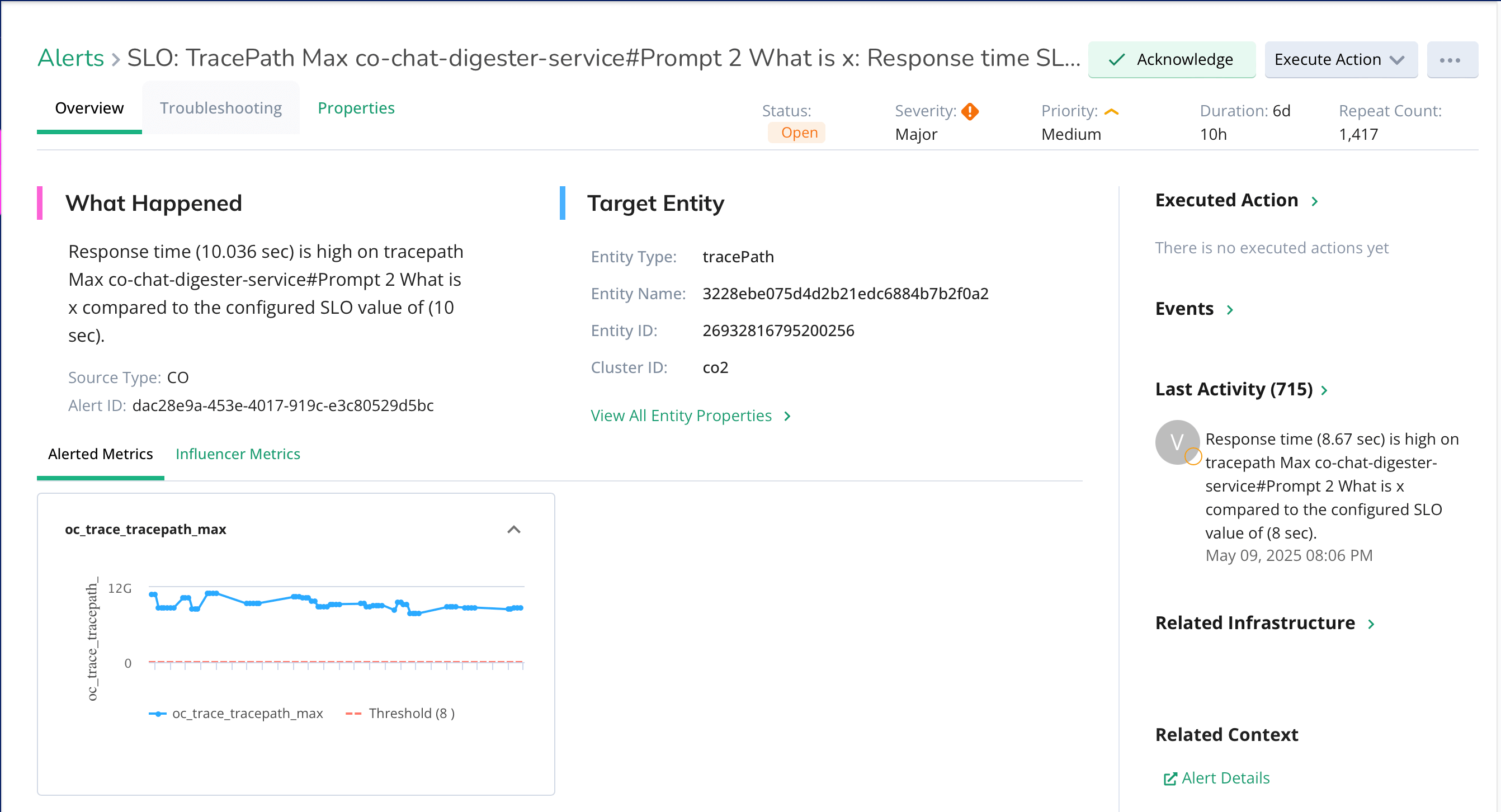
See Inside Every AI Interaction—From Pod to GPU to Performance Impact
Virtana traces the behavior of inferencing agents like LLMs and chatbots across your infrastructure—so you can optimize performance, reduce latency, and fix issues faster.

40% Reduction in Idle GPU Time
Real-time visibility and optimization lowered GPU underutilization across environments.Global FSI Customer
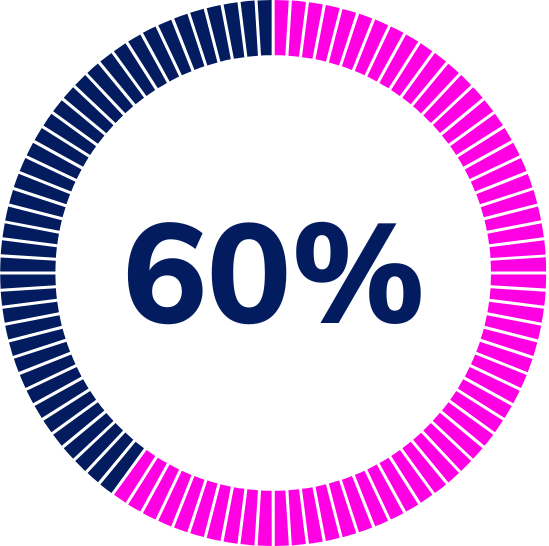
60% Faster Root-Cause Diagnosis
AIFO cut MTTR in half by tracing AI performance issues to infrastructure bottlenecks.Healthcare Provider

15% Lower Power Usage
Energy analytics revealed throttled GPUs, enabling targeted optimization and cost savings.AI Lab – USA
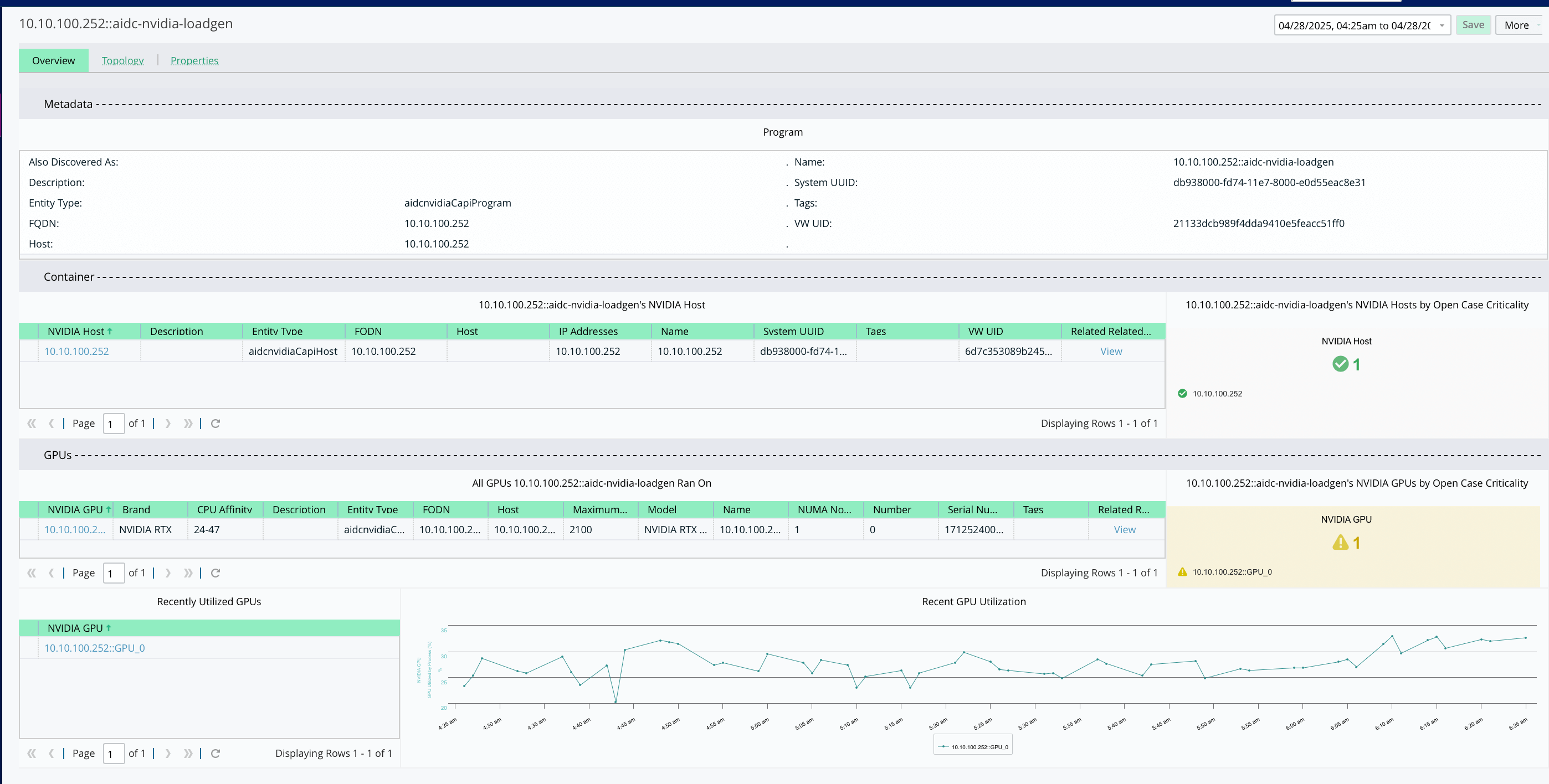
Trace Every Interaction Across the AI Stack
- Use OpenTelemetry to follow user requests through services, pods, and infrastructure.
- Correlate latency or failure to the exact node, GPU, or storage backend involved.
- Gain top-down visibility into every step of the inference workflow.
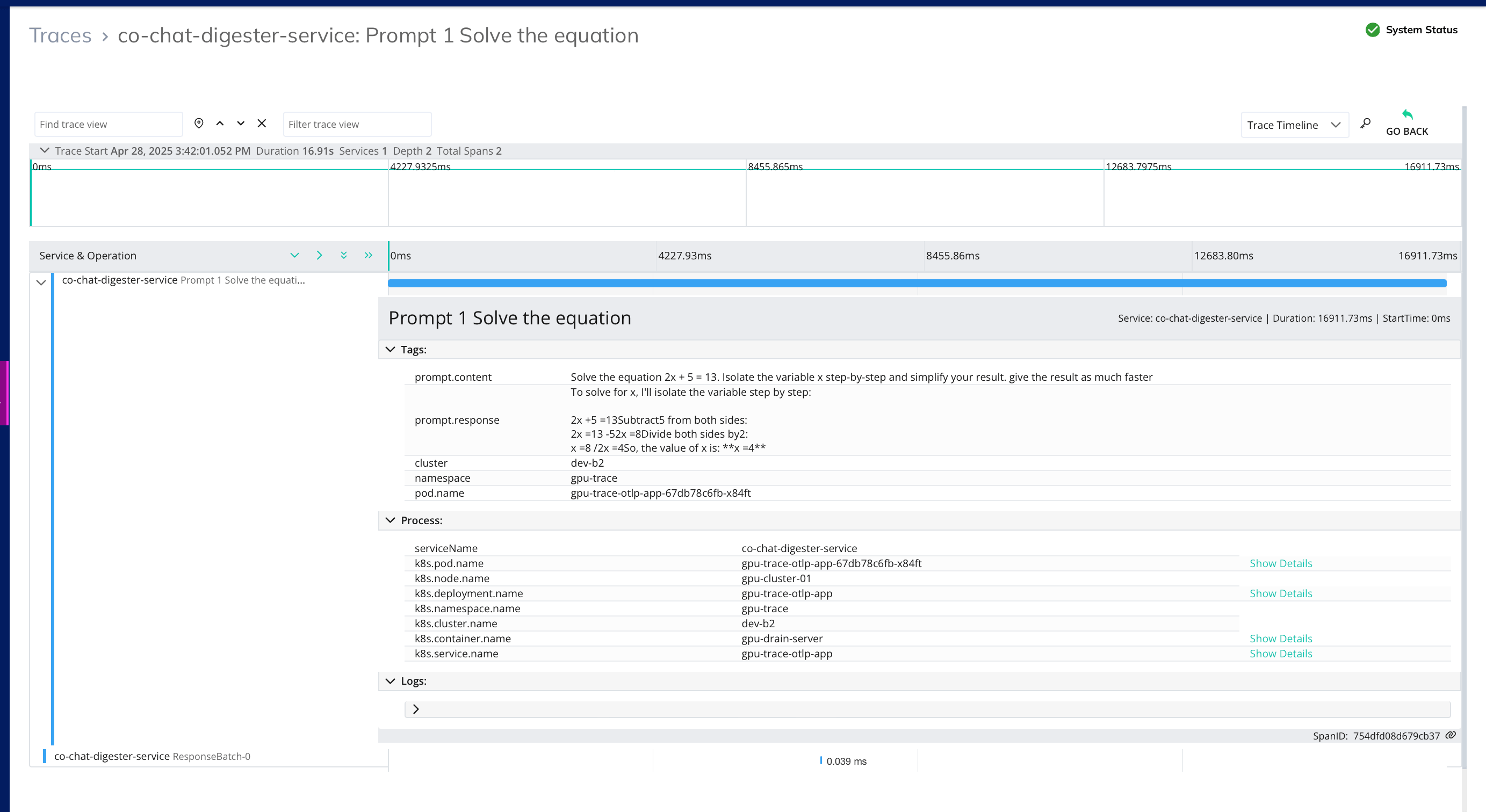
Monitor Inferencing Performance in Real Time
- Track response times, throughput, and resource usage across LLMs and chatbots.
- Identify slow or failing interactions before they affect user experience.
- Alert on abnormal behaviors with infrastructure context built in.
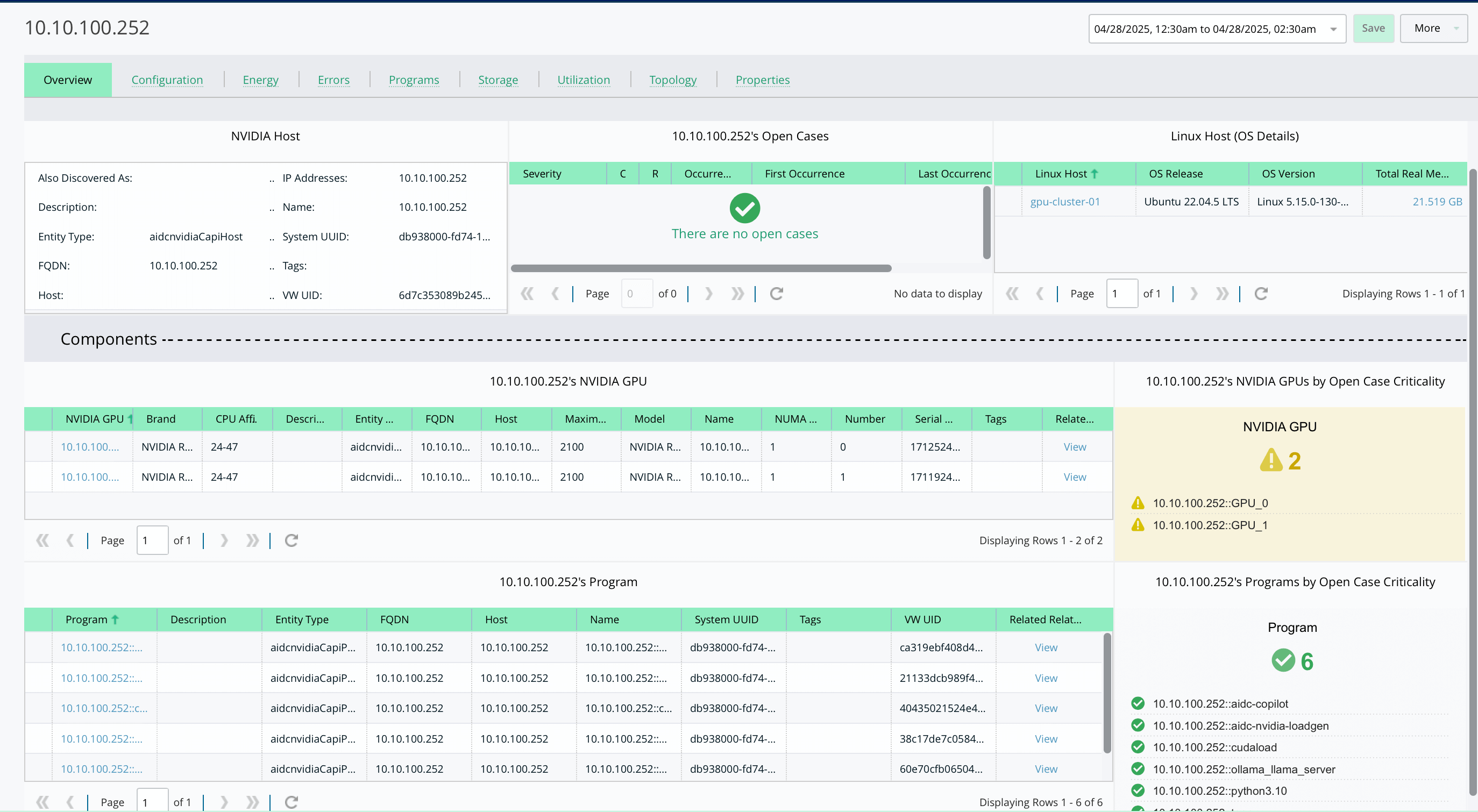
Correlate Agent Behavior with Infrastructure Activity
- Understand how underlying infrastructure impacts agent performance.
- Identify issues like storage spikes, GPU contention, or network congestion.
- Move from symptom to root cause in just a few clicks.
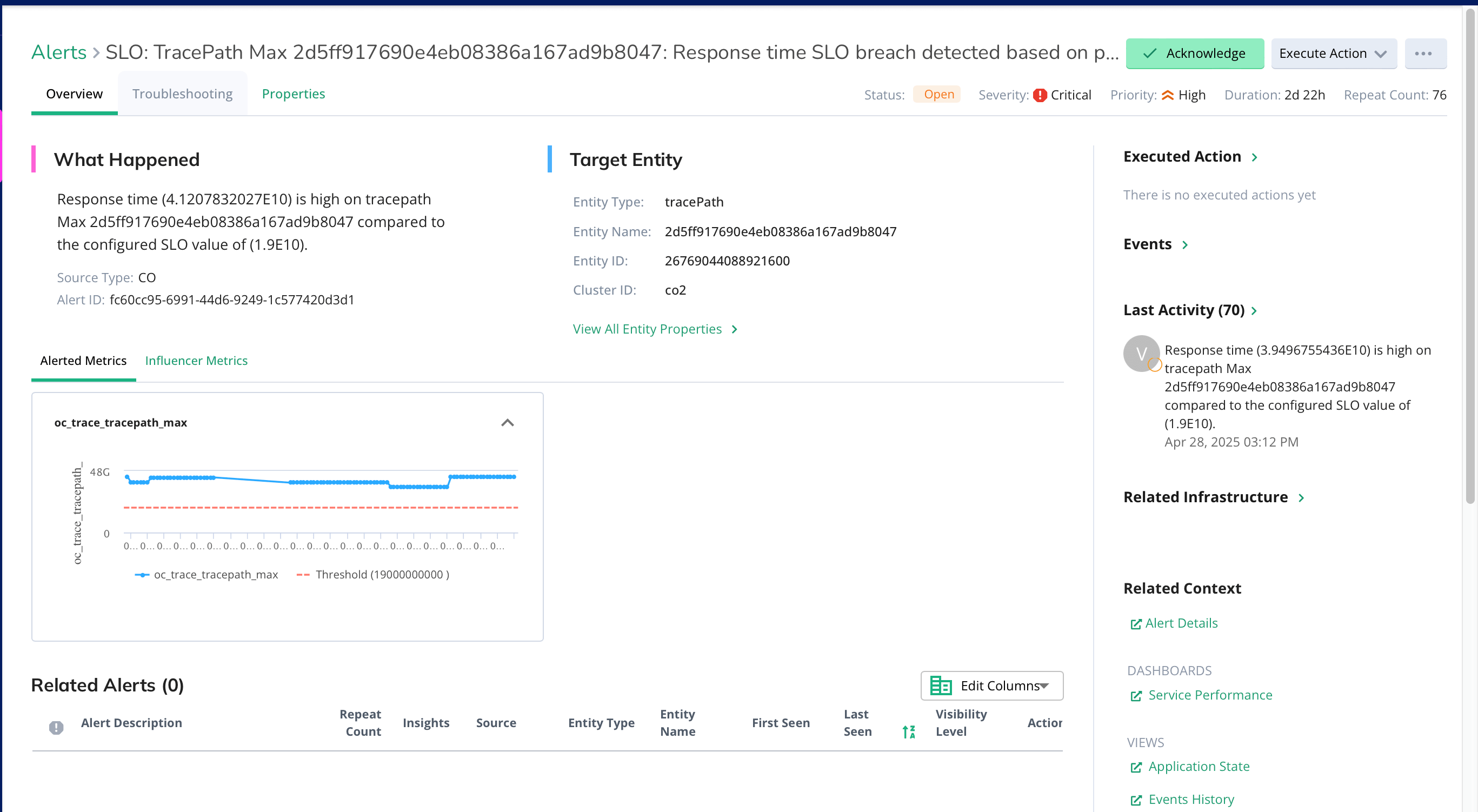
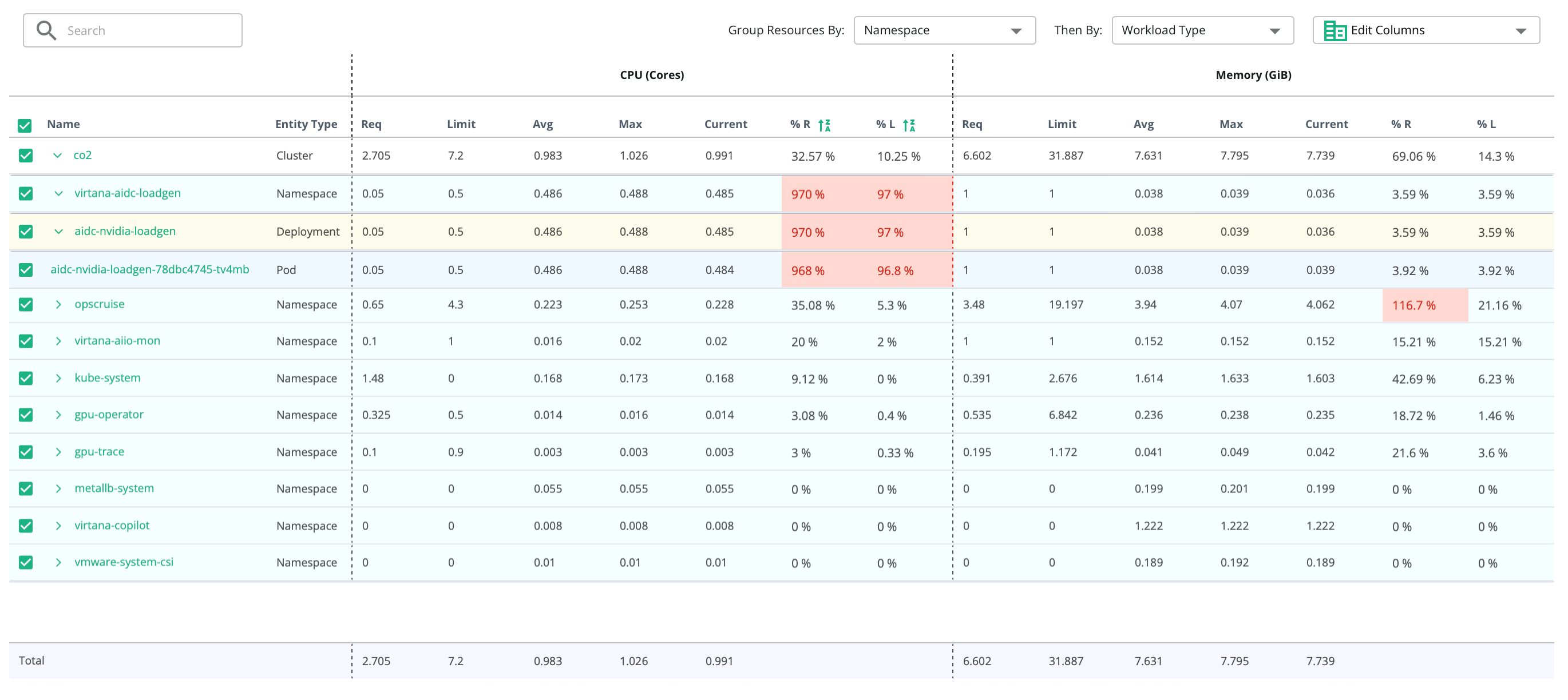
Optimize Pod Placement and Compute Allocation
- See where AI agents are running and how they’re scheduled across your clusters.
- Detect resource contention or poor placement that impacts inferencing speed.
- Improve cost and performance by optimizing agent deployment strategies.
Improve Service Reliability at Scale
- Continuously monitor the health and uptime of production inferencing services.
- Detect and resolve failures quickly—whether caused by code, config, or infrastructure.
- Keep SLAs intact, even as AI demand increases.