AI observability platform
Unlock Full-Stack Visibility for Your AI Workloads and LLM Applications
Virtana AI Factory Observability (AIFO) delivers real-time insight into every layer of your AI ecosystem—from infrastructure to LLMs and agentic workflows. By connecting performance, cost, and efficiency metrics across the stack, Virtana ensures resilient operations, predictable outcomes, and the agility to deploy new AI capabilities with confidence.

40% Reduction in Idle GPU Time
Real-time visibility and optimization lowered GPU underutilization across environments.Global FSI Customer
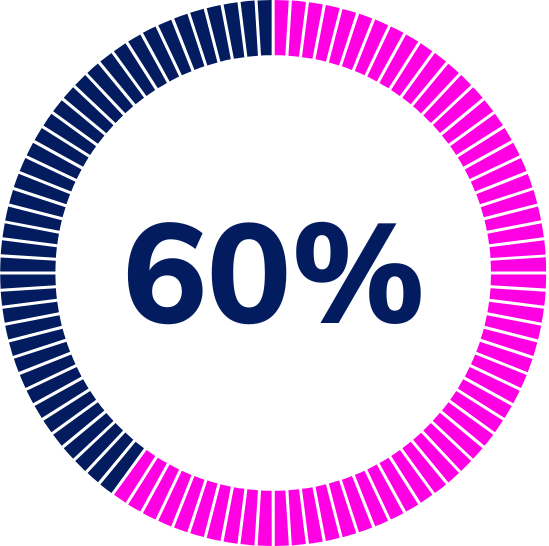
60% Faster Root-Cause Diagnosis
AIFO halved MTTR by tracing AI performance issues to infrastructure bottlenecks.Healthcare Provider

15% Lower Power Usage
Energy analytics revealed throttled GPUs, enabling targeted optimization and cost savings.AI Lab – USA
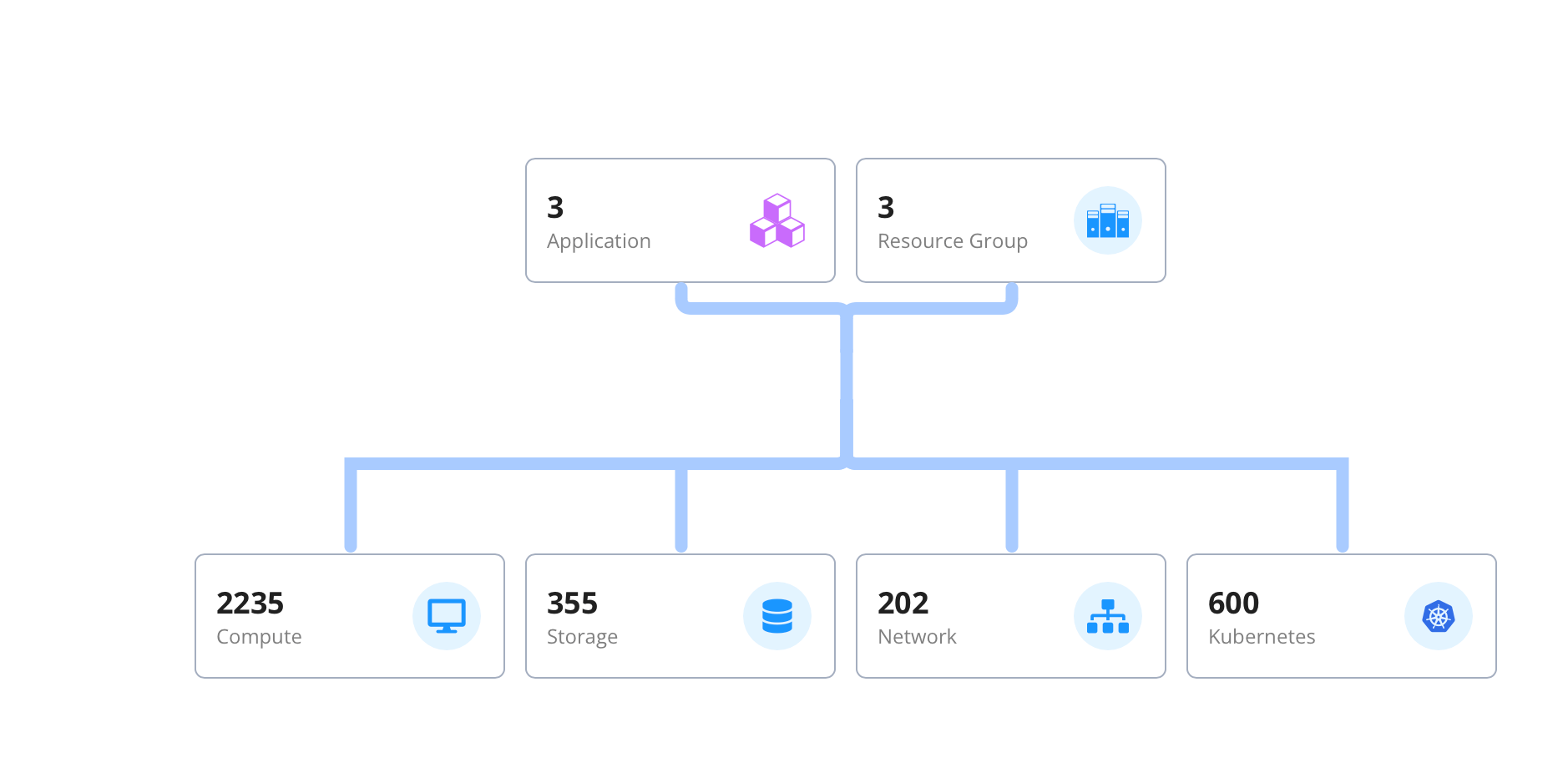
Correlate Infrastructure with AI Performance
Gain unified observability that ties infrastructure behaviour directly to AI workload outcomes.
- Map AI Jobs to Resources: Track every GPU, host, container, network, and storage element to achieve full-stack accountability and governance.
- Trace the AI Pipeline: Follow data flow from ingestion through model training and inference to maximize accuracy, efficiency, and ROI.
- Detect Dependencies Automatically: Identify interconnections across GPUs, jobs, and workloads to eliminate resource conflicts and optimize utilization.
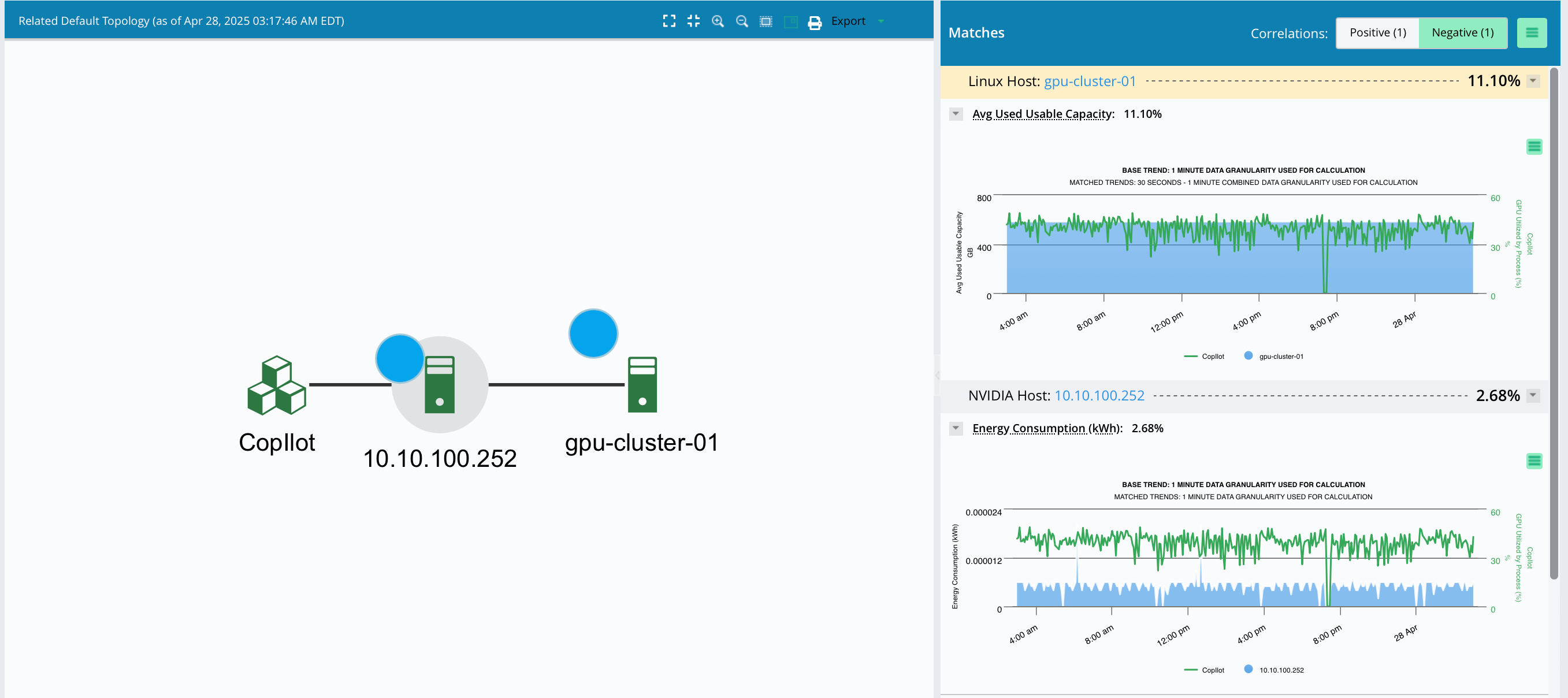
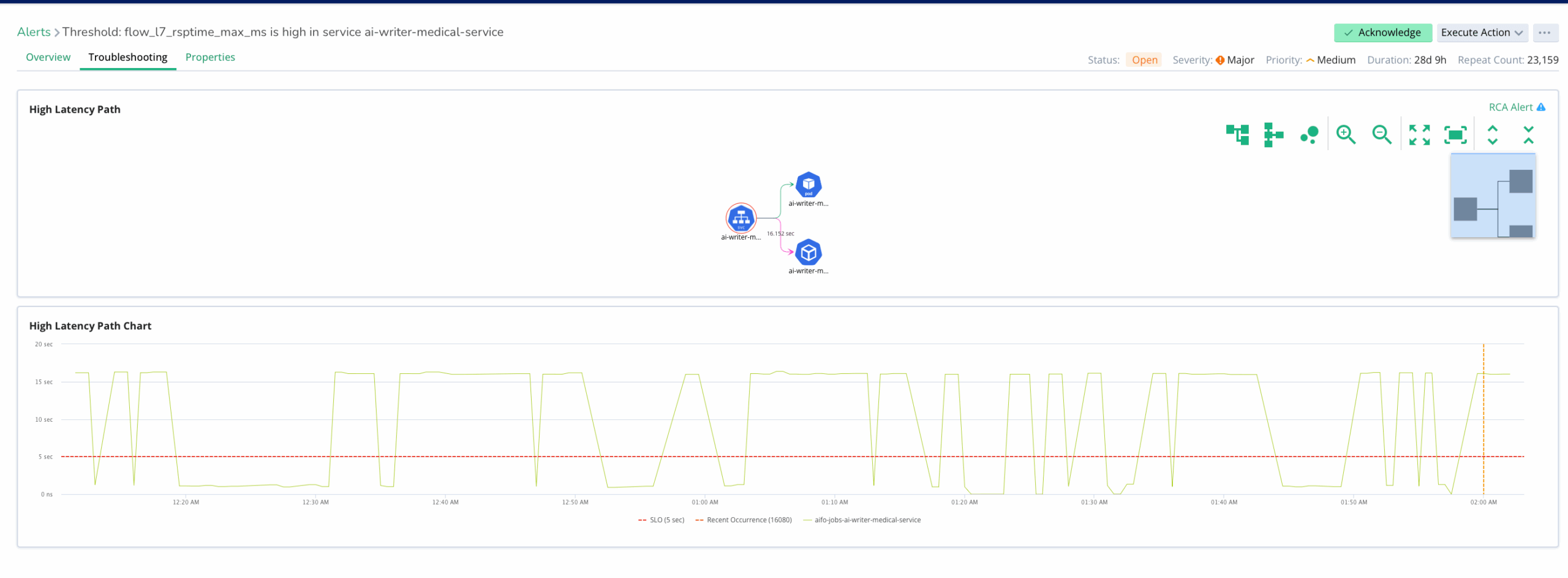
Accelerate Root-Cause Analysis (RCA) for AI Job Failures
Shorten investigation time and improve reliability with deep, correlated telemetry.
- Pinpoint Root Causes: Detect issues impacting training and inference such as GPU throttling, port resets, or switch outages.
- Reduce MTTR: Save days of debugging time by automatically identifying hardware, software, or configuration bottlenecks.
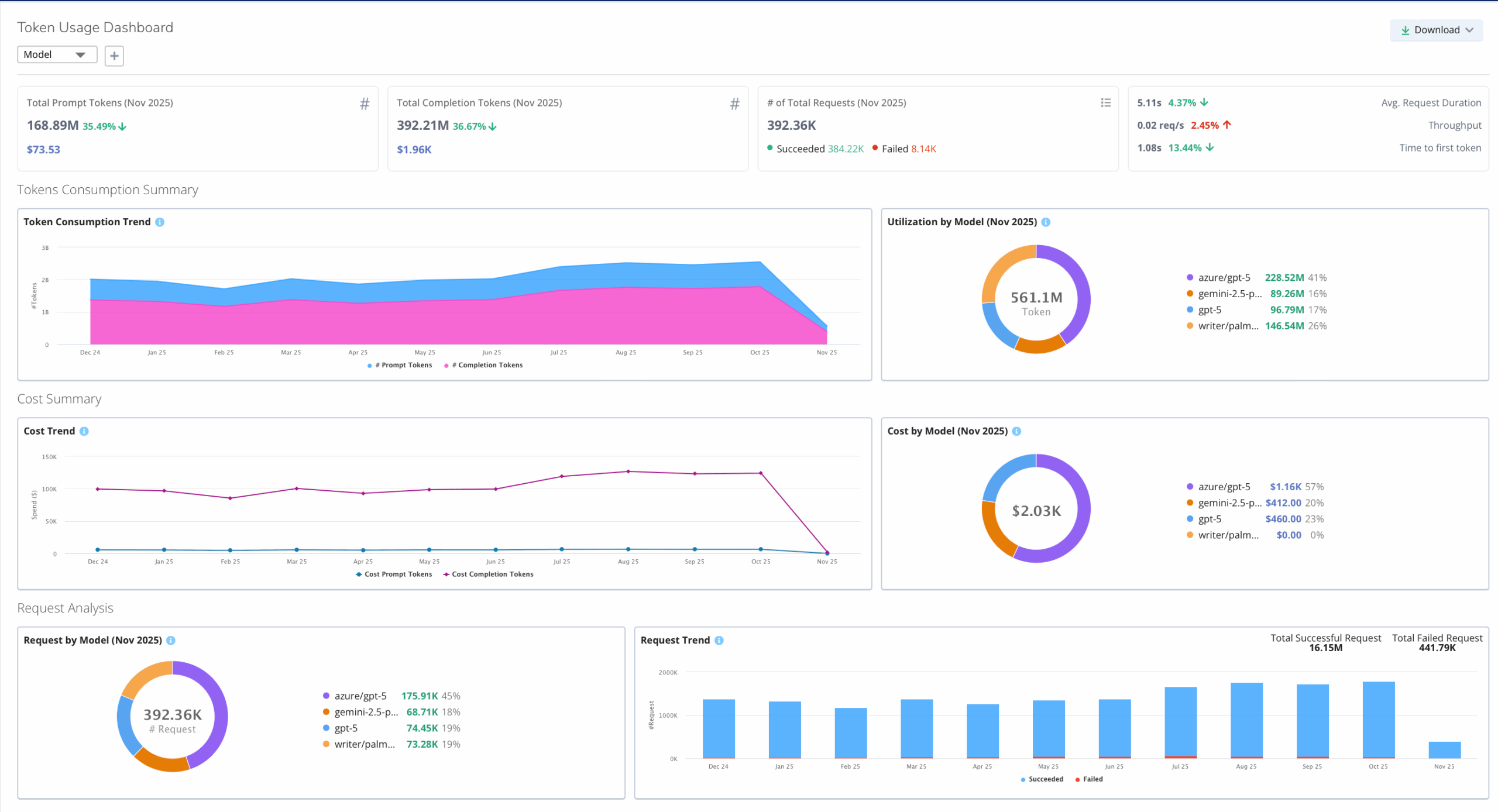
- Monitor GenAI Operations: Track token usage, cost, latency, and error rates across popular LLMs such as OpenAI, Llama and Gemini.
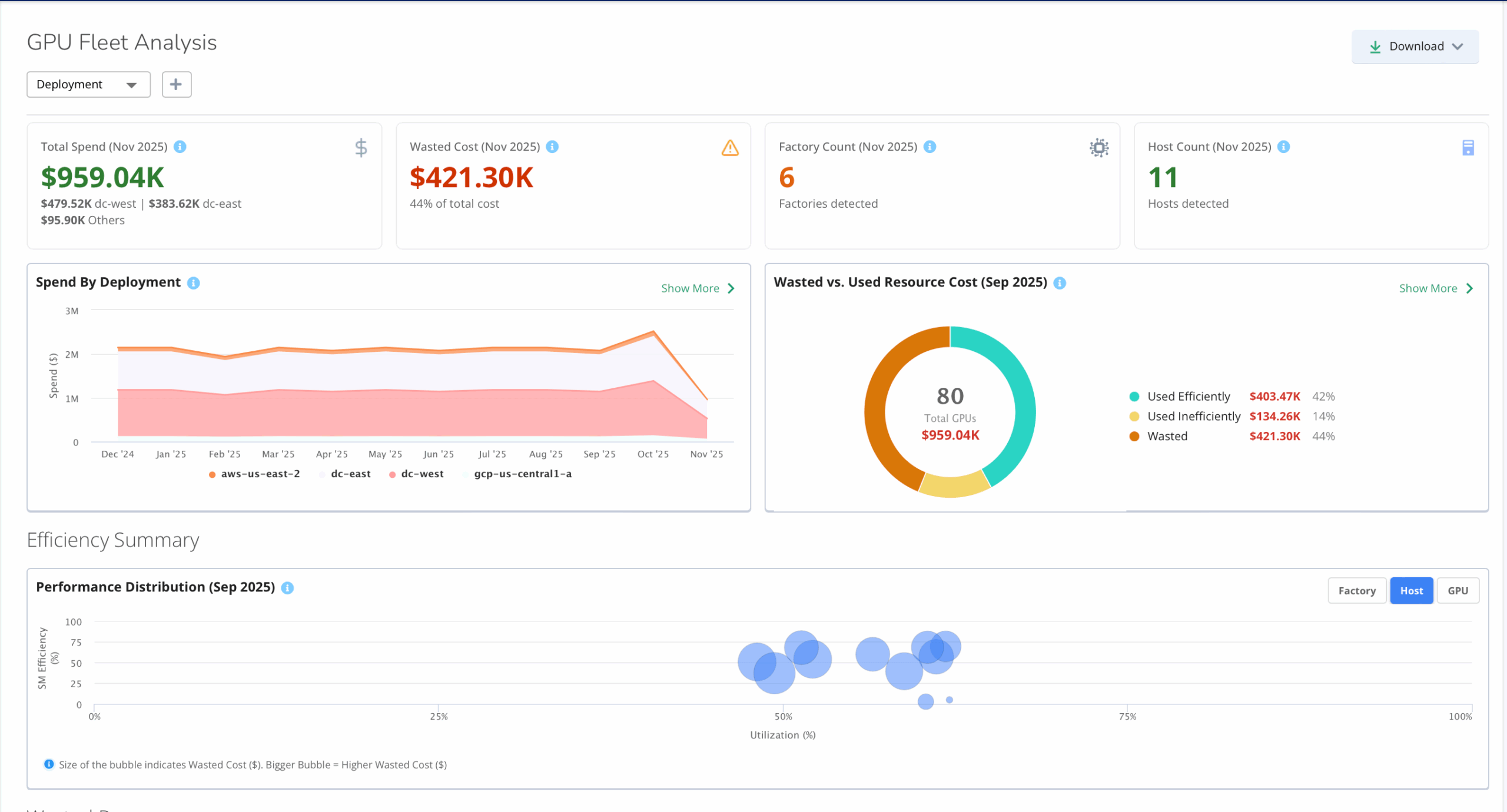
Monitor GPU Health and Performance at Scale
Ensure optimal GPU performance across diverse AI environments.
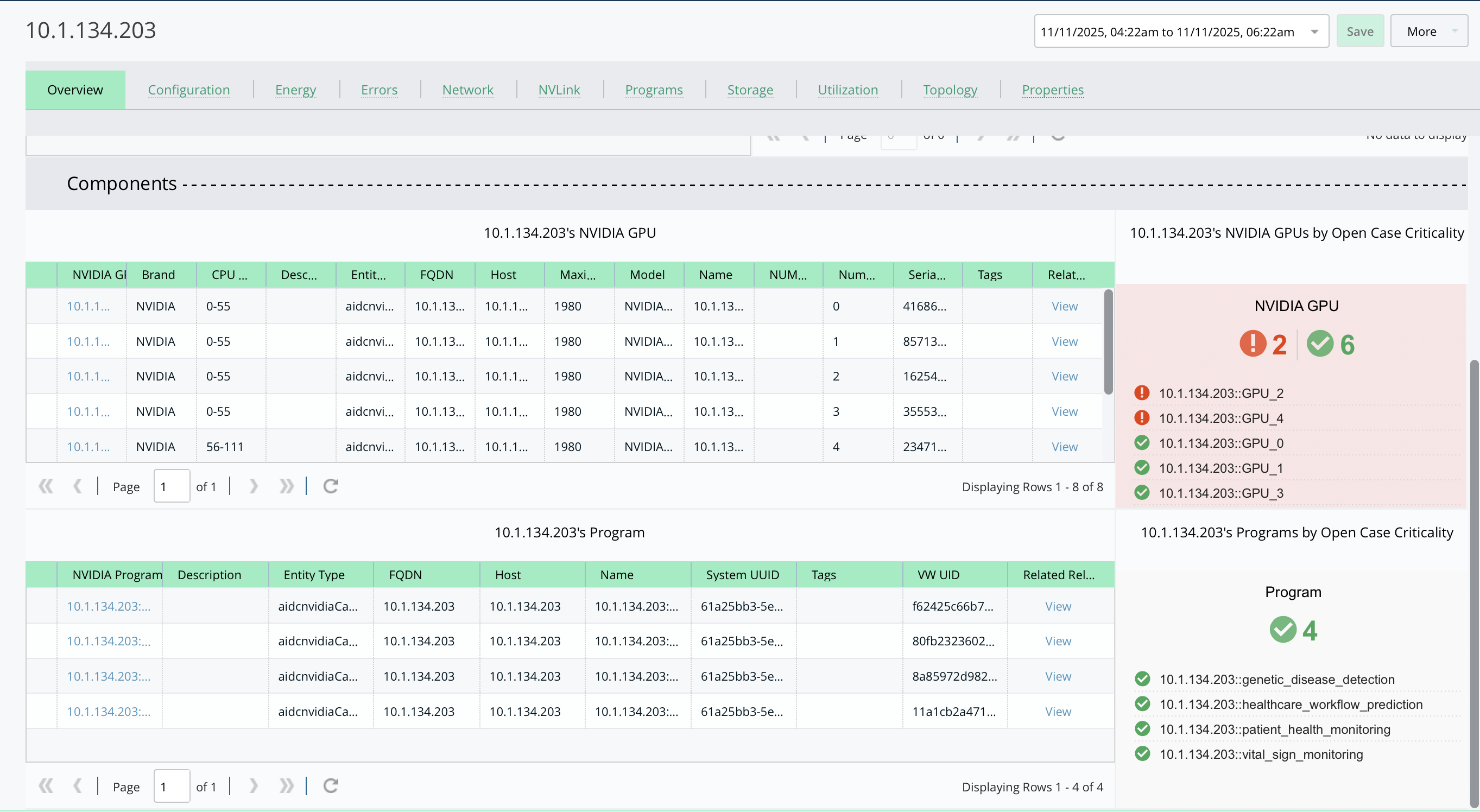
- Comprehensive GPU Insights: Measure utilization, thermal metrics, ECC errors, memory usage, and tensor core activity.
- Cross-Platform Visibility: Gain insights across hybrid and cloud-native deployments, including NVIDIA NIM containers,Neoclouds and AWS Bedrock.
- Proactive Issue Detection: Identify contention or thermal anomalies before they impact AI model performance.
Visualize Distributed AI Workloads and Bottlenecks
Understand performance dynamics across large-scale, distributed training environments.
- Profile Multi-Node Training: Identify stragglers, synchronization delays, and throughput inefficiencies.
- End-to-End Tracing: Use OpenTelemetry to correlate application performance with underlying infrastructure behavior.
- Compare and Optimize Models: Benchmark inference performance identify anomalies.
- Enhance Responsiveness: Analyze slowest LLM requests and error patterns to reduce latency and improve reliability.
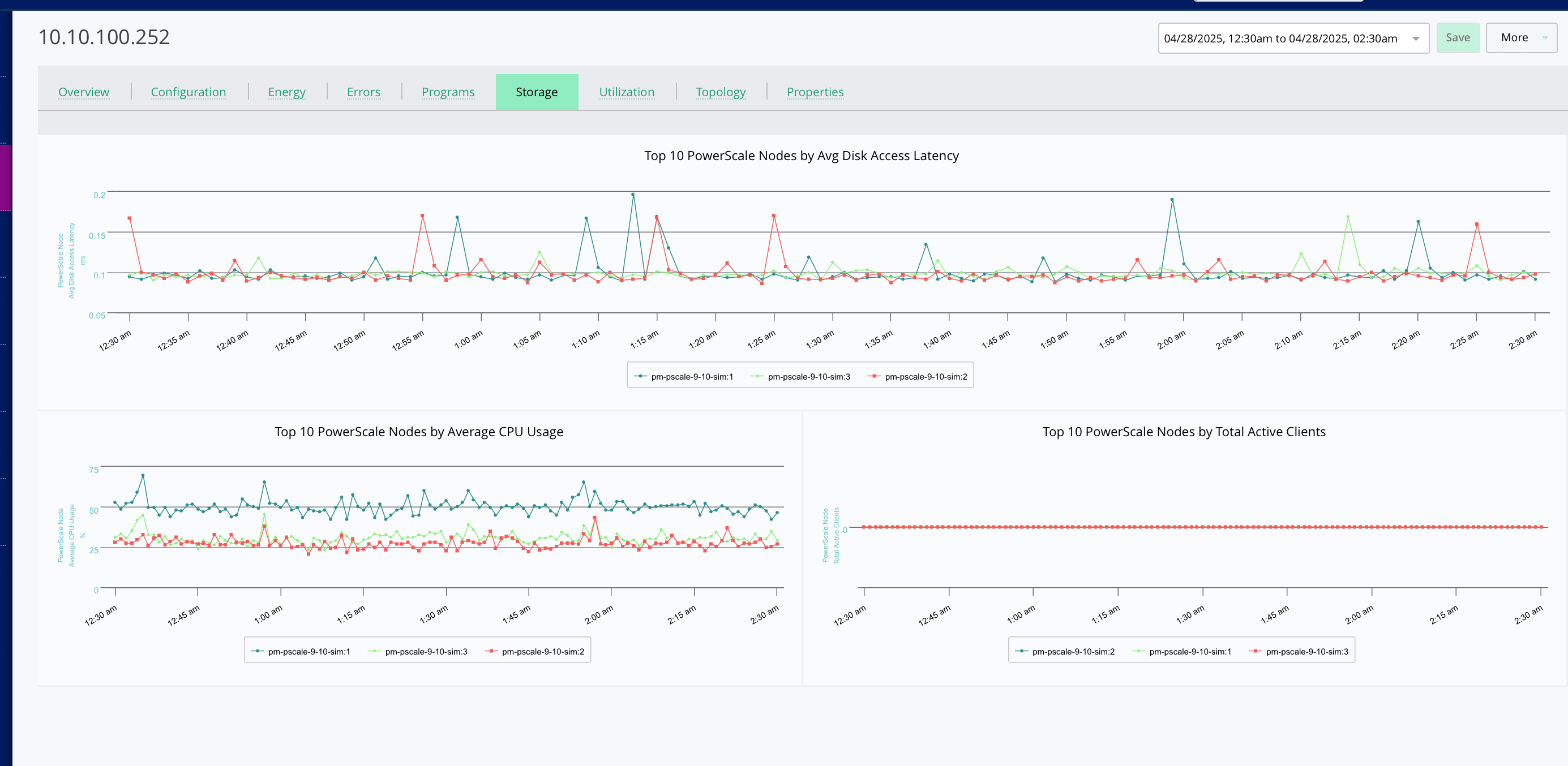
Identify Storage and Network Issues Impacting AI Pipelines
Uncover hidden bottlenecks that degrade inference or retraining performance.
- Detect Latency and Congestion: Monitor IO paths, packet loss, and switch port contention.
- Correlate Bandwidth to Model Throughput: Link network and storage metrics directly to pipeline performance.
- Prevent Pipeline Degradation: Proactively address issues before they affect SLA and model accuracy.
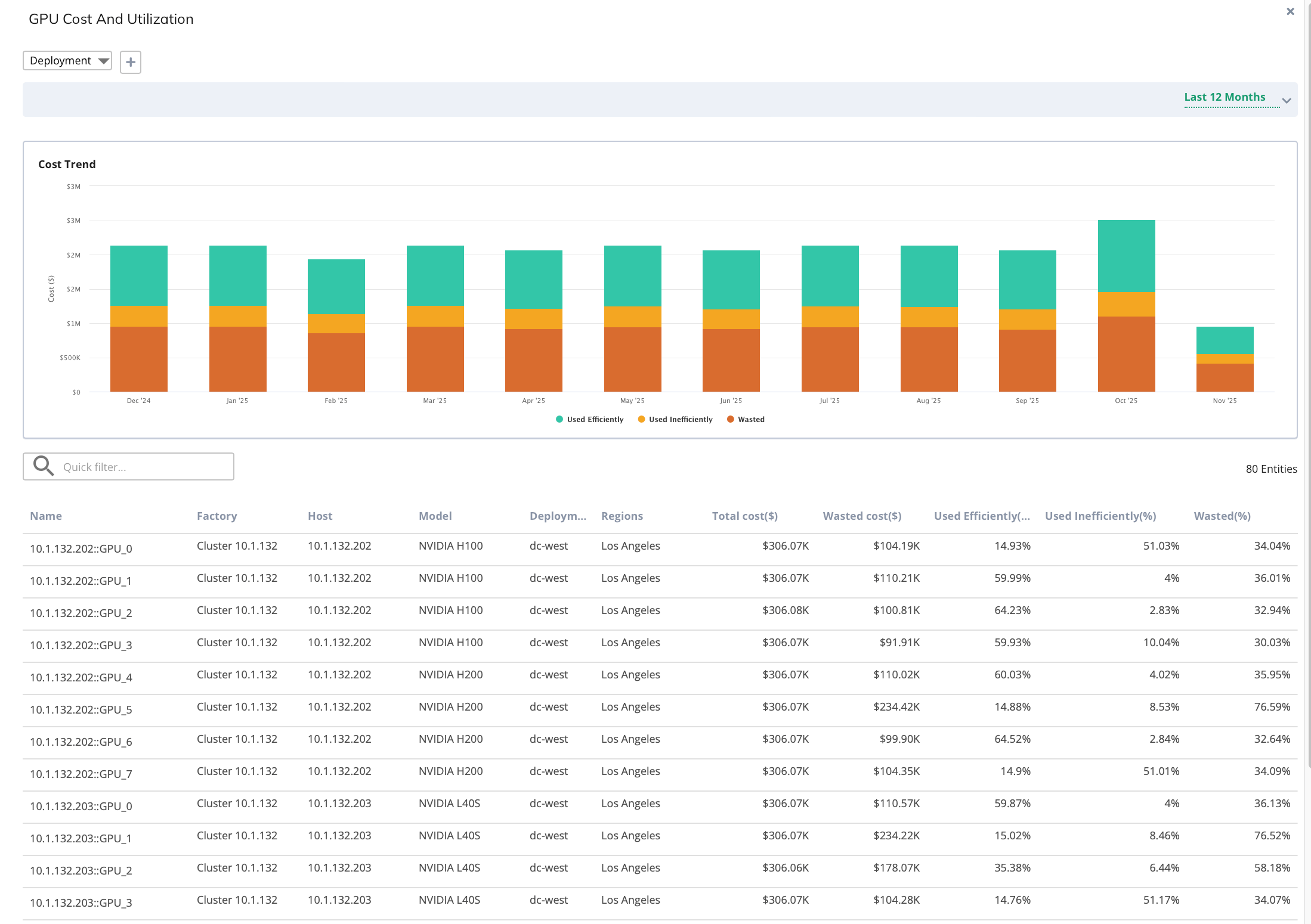
Improve Resource Efficiency and Cost Control
Drive smarter infrastructure utilization and sustainability across AI workloads.
- Eliminate Waste: Detect idle GPUs, misconfigurations, and underutilized hosts.
- Optimize Allocation: Right-size infrastructure to reduce overprovisioning and cloud overspend.
- Predict and Manage Costs: Track workload-level GPU and LLM expenses in real time.
- Support Sustainability Goals: Monitor temperature, power, and energy consumption metrics for greener AI operations.
Plan with Confidence Using Real-Time Telemetry
Leverage predictive insights for scaling and capacity management.
- Forecast Infrastructure Needs: Analyze GPU, network, and storage trends to anticipate future demand.
- Enable Proactive Planning: Use real-time telemetry to ensure readiness for next-generation AI workloads.
- Unify Hybrid Observability: Gain consistent visibility across on-prem, private, and public cloud environments.

Observe Every Layer of the AI Stack
Virtana AIFO provides unified observability across:
- AI/LLM Layers: Training, inference, and serving pipelines—on cloud or on-prem.
- Infrastructure Layers: GPUs, hosts, networks, storage, and orchestration layers.
- Operational Layers: Metrics, events, and traces for full lifecycle transparency.