EC2 Instance Types, The Ultimate Guide to AWS EC2
Basically, an EC2 instance is a virtual server that replaces on-site, physical hardware. In a matter of minutes, you can spin up and configure an EC2 instance—or hundreds of them—with just a few clicks. The process is pretty simple: select an instance image (called an AMI), choose an instance type based on desired performance, and then add any storage needed.
Don’t like your settings? They can be changed with ease. You just have to remember that when you terminate an EC2, your ephemeral storage (the storage that is part of your EC2) is erased, but if you use an Elastic Block Storage (EBS) then you can reattach your storage volume to the new EC2 once launched. You can also migrate certain instance types to other, better-suited performance families. The flexibility of changing EC2s ensures that you don’t have to fear spikes in usage or overpay for underused equipment.
What are the benefits of using EC2s?
There are several benefits to migrating to EC2 instances. Here are just a few:
- Elasticity: Capacity needs can be met within a few minutes.
- Control: Keep root access for your instances. Stop or terminate instances via the API.
- Reliability: Amazon commits to an EC2 Service Level Agreement of 99.99%
- Cost: Choose from several payment models to get the most affordable rate.
How many EC2 instance types are there?
With every configuration accounted for, there are over 400,000 different iterations of EC2. For now, we’ll stick to the basic differences you might come across when provisioning or working with EC2s.
AMIs
Amazon provides a list of 35 stock AMIs for you to choose from. These range from Amazon Linux, to Ubuntu, to Microsoft Windows Server, and even a Deep Learning AMI. If you can’t quite find what you’re looking for, there’s also a marketplace for selling and buying custom AMIs.
Instance Families
EC2s are primarily categorized by performance family:
| Instance Families | Example |
|---|---|
| Accelerated Computing | F1 instances have Field Programmable Gate Arrays (FPGA) that allow you to create a customized hardware acceleration platform for your application. |
| Compute optimized | C5d instances use the Intel Xeon Platinum 8000 series (Skylake-SP) processor that can reach a Turbo CPU clock speed of 3.4 GHz. |
| General Purpose | Offers instances with burstable CPU with T2 and T3 |
| Memory Optimized | High Memory Instances can contain up to 12 TB of memory and utilize bare-metal performance with direct access to host hardware. |
| Storage Optimized | D2 Instances can provide up to 3.5 GBps read / 3.1 GBps write disk throughput. |
What are the different types of EC2 Instances?
Within those greater families are unique instance types. Here’s a list of instance types for just the General Purpose Family:
- t2.nano, t2.micro, t2.small, t2.medium, t2.large, t2.xlarge, t2.2xlarge
- t3.nano, t3.micro, t3.small, t3.medium, t3.large, t3.xlarge, t3.2xlarge
- m4.large, m4.xlarge, m4.2xlarge, m4.4xlarge, m4.10xlarge, m4.16xlarge
- m5.large, m5.xlarge, m5.2xlarge, m5.4xlarge, m5.12xlarge, m5.24xlarge
- m6.large, m6.xlarge, m6.2xlarge, m6.4xlarge, m6.12xlarge, m6.24xlarge
Notice that T2, T3, M4, M5, and M6 are the different instance types, each having varying sizing options that range from nano to 24xlarge. From left to right, these instance types go from oldest to newest in generation. Over time, AWS deprecates the older generations.
If you’d like a full breakdown on instance types, check out our guide with 6 tips on selecting an EC2 instance type.
It’s important to pick carefully when choosing your AMI, Instance Family, and Instance type. All three of these components factor greatly when determining the overall price per hour Amazon charges you.
Speaking of pricing, let’s take a look at Amazon’s pricing options.
EC2 Instance Pricing Options
When it comes to paying for Amazon Web Services, there are four main purchasing options: On-demand Instances, Reserved Instances, Spot Instances, and Dedicated Hosts. Each pricing option is tailored to benefit a particular usage behavior.
Properly evaluating your environment to determine the best payment method for each instance is crucial to avoiding wasteful spending. But be careful not to get too aggressive when trying to save–choosing the cheapest available option is not always the smartest choice. Doing so may lead to performance issues for your application that would be difficult to diagnose in production (especially if it involves mis-allocation related to your disk I/O requirements).
After reading the following sections, you’ll have a clear understanding of when to leverage each pricing option
On-Demand Instances
On-Demand is the standard pay-as-you-use payment option. Usage is billed either per-hour or per-second, depending on the kind of instances being run.
On-Demand Instances are great for:
- Temporary projects
- Testing/Developing with EC2s for the first time
- Applications with unpredictable and spiky workloads
Essentially, these are a great first choice for anyone new to AWS who wants to learn without overcommitting. On-Demand Instances are also great for uncertain, flexible projects. This is because you’ll never have to pay for unused resources (which can happen with reservations) and your EC2 can still scale with growing workloads.
Spot Instances
You can obtain deep discounts of up to 90% by leveraging spot instances. How is that possible? It’s simple: spot instances are a limited pooled resource. They aren’t always available for the price you’re willing to pay. And when the price goes above your set bidding threshold, your spot instances are interrupted (via hibernation, stopping, or termination). So when choosing Spot Instances, it’s always best to pick fault-tolerant workloads and stateless distributed applications that can tolerate losing partial or full computing capacity without affecting your business processes.
Spot Instances are great for:
- Containerized workloads
- Big Data
- Test & Development workloads
Reserved Instances
For the forward-thinker, Reserved Instances are a great resource. You can save up to 75% in cost by choosing Reserved Instances over On-Demand ones. When using RIs, you also get the added optional benefit of reserving capacity in your preferred Availability Zones.
That sounds great, right? Why wouldn’t you just use RIs exclusively? Well, the downside is that you have to commit to a long-term contract of at least one year. This means continuing to pay a monthly amount even if your need goes away in six months. Also, to get the most savings possible, you have to pay upfront. That may not fit everyone’s budget.
Don’t worry, though. There’s also partial upfront and no upfront payment options for Reserved Instances–meaning you’ll still save on your EC2s, just not as much.
Reserved Instances are great for:
- Customers able to commit to 1 or 3 year contracts
- Applications that require steady state resources
- Applications that would benefit from reserved capacity
If you’re still unsure about committing to using RIs, consider the following:
- You can modify or exchange your reserved instances with convertible reservations
- Standard reserved instances can be put up for sale on the Reserved Instance Marketplace
Want to know more about AWS Reserved Instances?
Check out our AWS Reserved Instances guide!
Dedicated Hosts
Still like the idea of having your own physical server and have full control of your hardware? Dedicated Hosts are your solution. AWS offers dedicated physical EC2 servers through the On-Demand and Reserved Instance payment methods.
Dedicated Hosts are great for:
- Avoiding the sharing of physical computing resources with other AWS customers
- Using your existing server-bound software licenses
- Meeting compliance requirements
Note that AWS also offers Dedicated Instances (vs. Hosts).
The difference is that Dedicated Instances may be provisioned on a different physical server each time (preventing you from using your own software licenses tied to a specific socket, core, or CPU serial number).
How Does AWS Charge for EC2s?
In October of 2017, AWS announced that Amazon EC2 usage of Linux-based instances launched in On-Demand, Reserved, and Spot form (along with provisioned EBS volumes) will be billed on one second increments, with a minimum of 60 seconds. This means that you would no longer pay for a full hour if you only use the instance in a running state for a few minutes. You also get the benefit of reserved instance pricing for multiple instances used within the hour. Remember that AWS EC2 pricing may still be expressed in the form of instance-hour on many of their pricing pages to preserve consistency.
Dedicated Instances, EBS Snapshots, and products in AWS Marketplace are still billed on an hourly basis.
Data Transfer Costs
Data transfer costs can be divided into two general categories:
- Data transfers in between AWS services (like from EC2 to S3)
- Across Availability Zones in Same Region:
$0.01/GB each direction - Within Same Availability Zone:
typically free - Across Regions:
varies by region
- Across Availability Zones in Same Region:
- Data transfers from AWS to the public internet
- IPv4 (Public or Elastic)
$0.01/GB either direction - IPv6 in Different VPS:
$0.01/GB either direction - Regional Out To Internet:
varies by region
- IPv4 (Public or Elastic)
The more data that is sent out from AWS, the less expensive it gets. Here are the current pricing tiers: 1GB, 9.999TB, 40TB, 100TB, 150TB, 500TB. AWS allows you to commit to a volume of data transfer per month in exchange for a more favorable pricing.
Remember, each of these tiers will have different pricing values for each region.
One-Time Dedicated Instance Costs
Dedicated Instances have two main costs:
- Per hour instance usage fees for each instance running
- Price varies by Region and AMI
- Per hour dedicated region fee for each region being used
- $2 per region used regardless of the number of instances in them
How to Minimize Data Transfer Costs
A typical need for data transfer across Availability Zones or AZ (considered regional data transfer by AWS) or Regions is high availability. You may have a Cassandra ring for storing time-series data and provision it to span multiple regions in order to be resilient to any natural disaster, outages, or performance problems in a single geographic region
If resiliency is not your objective, then you can eliminate the data transfer fee by launching your EC2s that are transferring data within the same Availability Zone as long as you are using a private IP address (vs. Elastic IP address). Note that you can also reduce the fees by choosing different regions or by transferring data across AZs instead of across full Regions.
Looking for a tool to make your savings journey easier? Consider Virtana Cloud Cost Management’s AWS Cost reports.
We’re very proud of the granularity they provide, on a per-instance level, to help you reduce spend and proactively dodge unwanted surprises in your bill.
II. Intermediate
More About Instance Types
Burstable Performance Instances
Burstable Performance Instances (T2, T3) are unique in their ability to perform beyond their baseline CPU ability. This flexibility in performance is achieved through tracking CPU Credits that accumulate over time. When credits run out, their performance returns to its baseline and the accumulation cycle continues.
How CPU Credits are Accumulated:
- T2
Accumulates CPU credits at a constant rate depending on instance size and when idle.
- T3
Accumulates CPU credits when workload is beneath baseline CPU performance.
The accumulated credit which is available to monitor via a CloudWatch metric can be used to burst above the baseline performance level before the credit is exhausted. (Note that you would need to use AMIs with device drivers that would support this functionality.)
Both T2 and T3 Burstable Performance Instances can utilize Unlimited Mode, which allows the instances to indefinitely perform above baseline at an additional cost. T2 Unlimited Instances, for example, use the following formula to determine added cost:
5 cents : vCPU-hour ∗ instance count ∗ %above baseline ∗ hours above baseline
T instances were built for scenarios where high CPU performance is infrequently needed but incredibly useful in certain moments. Their ideal use cases are web servers, developer environments, and small databases.
Storage Options
There are a few storage options you should familiarize yourself with that can be used with or without an EC2. The solutions range from block storage (EBS), object storage (S3 and Glacier), file storage (EFS), and Gateways for connecting your on-premise systems to the cloud.
Instance storage
Also referred to as “ephemeral” storage, Instance Storage is the hard drive that is connected to your EC2 which deletes upon termination of your EC2 instance
Block storage with Amazon Elastic Block Storage or EBS
EBS is the equivalent to Direct Attached Storage (DAS) or Storage Area Network (SAN). A block-level storage volume made for single-instance attachment and up to 16 TB of storage space. Good for frequent updates (databases). EBS storage persists separately from your running EC2 instance similar to a networked hard drive mounted as a storage volume.
| Type of EBS | Description |
|---|---|
| Provisioned IOPS SSD (io1) | Specialized, low-latency storage with reserved amount of IOPS up to 32k IOPS per volume, ideal for real-time NoSQL |
| Compute Optimized | Default general purpose storage with low latency and up to 10k IOPS per volume |
| Throughput Optimized SSD (st1) | Inexpensive storage with only up to 500 IOPS per volume, ideal for data warehouse and log processing |
| Cold HDD (sc1) | The least expensive EBS solution with up to 250 IOPS per volume, best for data that requires fewer accesses per day |
| Storage Optimized | Saves point-in-time snapshots of your volumes to Amazon S3 and incremental backups and ability to restore an EBS from the snapshot. Great for backups or storing EBS content at a cheaper rate before you restore it again into a new EBS. |
File storage with Amazon Elastic File Storage or EFS
EFS is a shared file system designed to provide massively parallel shared access to thousands of Amazon EC2 instances, enabling your applications to achieve high levels of aggregate throughput.
Object storage with S3 and Glacier
- Amazon S3:
Static data storage with max capacity of 5TB per bucket; data is accessed using object keys. It is accessible via multiple interfaces including a web-based interface for easy browsing by end users. It’s also highly available and architected to store data redundantly across multiple devices and geographies. Data charges are split between storing, reading, and writing your data.
- Glacier:
This the cheapest storage solution for long-term archived data that doesn’t require frequent (or low-latency) access. Data retrieval charges come in three forms: standard, expedited (you pay up to 20x more for fast retrieval), or bulk.
AWS Storage Gateway
This is an appliance that you deploy on-premises and used to migrate or augment your on-premise storage with cloud storage. It connects into your computing hardware with a standard interface and stores the data in S3 buckets or as EBS snapshots.
EBS-Optimized Instances
EBS optimization simply means that your EC2 instance is empowered at all times to take full advantage of the IOPS provisioned on its attached EBS volume. Newer instance generations (C5, C4, M5, M4, P3, P2, G3, and D2) have EBS optimization turned on by default at no additional cost.
But what if you’re using older instances?
For all other instance types not listed above, enabling EBS optimization on your EC2 incurs an hourly added fee. Here’s an easy way to remember the information below: each size up basically doubles the hourly cost.
EBS-Optimization Cost Per Hour on Previous Generations
| General Purpose | Memory Optimized | Compute Optimized | Storage Optimized | GPU Instances |
|---|---|---|---|---|
| m3.xlarge – $0.25 | r3.xlarge – $0.02 | c3.xlarge – $0.02 | i3.xlarge – $0.02 | g2.2xlarge – $0.02 |
| m3.2xlarge – $0.05 | r3.2xlarge – $0.05 | c3.2xlarge – $0.05 | i3.2xlarge – $0.05 | |
| r3.2xlarge – $0.10 | c3.2xlarge – $0.10 | i3.2xlarge – $0.10 |
Keep in mind that this hourly cost is in addition to your other hourly EC2 instance fees.
Cluster Networking
Setting up a cluster placement group is great for creating low-latency networks between all instances within a cluster. Traffic between clustered instances within the same region can achieve up to 5 Gbps for single-flow and 25 Gbps for multi-flow traffic in either direction. If you’re launching high-performance analytic systems or complex science and engineering applications with high data transfer between nodes, Cluster Networking is a great solution.
Picking The Right EC2 Size
With so many EC2 types and sizes, choosing one that’s just right is quite a challenge. This is especially true when you toss in the added complexities surrounding storage options or specialized use case requirements. And let’s not forget the difficulty in deciding whether a 1-3 year reservation contract is worth the up-front cost for long-term savings.
Rushing into your migration and “playing it safe” by provisioning oversized or overpowered EC2s may get you into the cloud faster, but your infrastructure spend is going to be higher. That’s guaranteed.
So, what should you do to plan the rollout of your EC2 instances?
1. Start with what you know: how your application is consuming computing resources today. You are going to measure all server resource utilization of CPU, memory, disk I/O, and network I/O.
2. Monitor this data for 2-4 weeks to account for seasonal patterns and spikes. You can start monitoring CloudWatch metrics and use the AWS Amazon CloudWatch scripts or use other open source agents (such Diamond for Linux or CollectdWin for Windows) for more granular data (including memory, which is not provided by CloudWatch).
3. Record the allocated capacity of CPU, memory, network, and IOPS based on the attributes of each of your EC2s (available in AWS console). The most difficult allocation to calculate is disk IOPS since it depends on the IOPS ratings of one or more EBS volumes attached to your EC2. Once you have this information, you are ready to compare the consumed resource against the allocated resource.
4. Graph your historic data, instance by instance, and eyeball the graphs for the points of resistance. Determine if the highest level of resource utilizations are due to application workload during peak hours or merely spikes caused by a midnight backup.
5. When dealing with multiple instances, viewing one graph at a time is time consuming. Instead, download your data as a spreadsheet and aggregate it over time. You want to show a single value for each metric which represents the minimum, 5th percentile, mean, 95th percentile, and maximum over the last 2 to 4 weeks. This allows you to isolate all over- and under-provisioned instances.
6. We recommend that you use the agent in step 2 to measure CPU load (AKA run queue), I/O wait, and disk latency to isolate performance problems due to capacity bottlenecks.
7. You can now select the appropriately typed and sized EC2 for your instances according to workload requirements.
If all of that sounds like a lot of work, well, it can be. But it doesn’t have to be. Most of the heavy lifting can be done through Virtana Cloud Cost Management’s Utilization and Cost vs Utilization reports. We even have recommendation reports for EC2s and ASGs to help automate that final process between reviewing your aggregated historical workload data and inferring which EC2 instances are best suited to your needs.
Interested in automating the bulk of your capacity planning with our personalized EC2 sizing recommendations? Try Virtana Cloud Cost Management for free. Sizing up your needs before migrating to the Amazon cloud platform is important, but don’t forget that right-sizing is an ongoing process. Your infrastructure should continue to evolve as your business grows and workload patterns change.
Based on Performance Data
As outlined in the previous section, performance data is critical for accurate capacity planning. This data helps inform your choice between EC2 instance families, each specialized in meeting different workload needs.
In this section, we’re going to explore compute and storage optimized use cases.
- Find instances with a max CPU and memory usage of less than 40% over a four-week period.
- Focus on very recent instance data and on instances that have run for at least half the time you’re looking at.
- Ignore burstable (T2 and T3) instances because these are designed to run at low CPU percentages for significant periods of time to accumulate CPU Credits.
Storage Optimized
The new storage-optimized instances such as the D2 include up to 48 TB of local HDD-based storage that must be considered in your pricing decisions even though it’s ephemeral (deleted when you terminate your instance). However, for right sizing Storage Optimized instances, IOPS is a key metric to measure. Consider these two points of advice from AWS when analyzing your data:
- Use the following formula to convert Peak NetworkIn and NetworkOut metrics from bytes per minute to megabits per second:
Maximum Networking (or NetworkOut) ∗ 8 ∕ 1024 ∕ 1024 ∗ 60 = Number of Mbps
- Notice how I/O and CPU percentage metrics change during the day and whether there are peaks that need to be accommodated.
Sometimes, even when I/O performance is important, you have to play it smart. For one particular use case at Virtana, we had to choose between the alluringly powerful i3 instances (which use ephemeral storage) and a safer–but less powerful–combination of m5 instances and Amazon EBS volumes.
Designed for I/O-intensive workloads, i3 instances are equipped with NVMe SSD storage. They can deliver over 3 million IOPS in 4 KB blocks and a sequential disk throughput of up to 16 GBps. Basically, i3s are storage-optimized instances perfect for very large deployments.
But while the i3 solution is powerful, for our use case it carried with it a higher risk of failure due to its limited instance store. Ultimately, we chose the m5 + EBS combination because of its greater survivability. m5 instances can be stopped and volumes resized without losing any of their data–a valuable feature which ultimately won out in our decision making.
The important takeaway here is this: even though an m5 is categorically considered a general-purpose instance type, it was the right move for our storage survivability use case based on our historical performance data.
Considerations When Switching Instance Families
If you’re already situated in the AWS ecosystem and looking for ways to improve your infrastructural spend, consider switching up your instance families. You can migrate to different models of the same instance family or, depending on certain attributes, switch to another instance family entirely.
However, there are some important details to consider when switching to a new instance type:
- Virtualization type
Not all versions of your operating system can run on the latest instance types. In some cases, you must first upgrade your operating system before you can switch to a new type that uses the latest virtualization hypervisor technology used by AWS.
This page explains the Linux AMI virtualization types and dependencies.
- Platform
You must pick an instance type that supports 32-bit AMIs if your existing instance type does as well.
- IOPS ratings
There are times when an instance type may have a hardware limitation for supporting certain EBS ratings. AWS provides this information and they must be reviewed prior to your selection.
- AMI limitations
Certain AMIs have dependencies by type and size. For example, SQL Server Enterprise 2017 on Linux requires at least 4 GiB of memory which must be factored into your selection.
- Network Interface Card (NIC) throughput
If you depend on a high volume of network activity then you must ensure that your instance type can support it. For example, some families support enhanced networking with up to 10 Gbps such as the C3, C4, D2, I2, and R3 families.
III. Advanced
Pairing EBS Volumes
When first introduced, an AWS EC2 only came with local ephemeral storage. However, over time, various flavors of Elastic Block Store (EBS) volumes were introduced that could be paired with an expanding list of EC2 selections. Below is a summary of EBS history:
2006 — EC2 launched with instance storage.
2008 — EBS (Elastic Block Storage) launched on magnetic storage.
2012 — EBS Provisioned IOPS and EBS-Optimized instances.
2014 — SSD-Backed general purpose storage.
2014 — EBS data volume encryption.
2015 — Larger and faster EBS volumes.
2015 — EBS boot volume encryption.
2016 — EBS Throughput Optimized HDD (st1) and Cold HDD (sc1) volume types.
At present (November 2018), when it comes to selecting an EBS volume, there are four main storage options to choose from. Choosing between them requires weighing pros and cons concerning speed, size, and cost.
| EBS Volume | IOPS/vol | Throughput/vol | About | Common Uses | Price |
|---|---|---|---|---|---|
| Cold Storage HDD (SC1) | 250 IOPS | 250 MB/s | Used for infrequently accessed data | Colder data requiring fewer scans per day. | $0.025 GB/mo |
| Throughput Optimized HDD (ST1) | 500 IOPS | 500 MB/s | Used for active workloads | Data warehouses and log data | $0.045 GB/mo |
| EBS General Purpose SSD (GP2) | 10,000 IOPS | 160 MB/s | Used for speedy delivery on simple data | Transactional applications and quick-deploy instance images | $0.10 GB/mo |
| EBS Provisioned IOPS SSD (IO1) | 32,000 IOPS | 500 MB/s | Used for intensive applications and speedy delivery | Active data warehouses and relational databases | $0.125 GB/mo |
For higher performance, remember to also consider using RAID configuration for Linux and Windows, and read RAID Configuration on Linux and RAID Configuration on Windows to learn more.
Using Spot Instances
Before we diving into use cases, let’s take a minute to review how Spot Instances work and where their resources come from. Spot Instances are comprised of unused AWS infrastructure within a given capacity pool. Every capacity pool has its own price, determined by the resources available.
Capacity Pool Overview
A capacity pool is one given instance type + size in an availability zone. Below is an example containing 36 capacity pools across 2 availability zones in Region A: 17 of the pools are unavailable at the moment of inspection in Region A. Let’s say you wanted r5.24xl and, as you can see, it’s not available in either zone. You might be tempted to back out and just pay for an on-demand instance, but wait. Staying flexible is the key to being successful with Spot Instances.
The Importance of Being Flexible
Get the most out of Spot by staying flexible in these three ways:
Instance flexibility
If you have specific vCPU and memory requirements, use combinations of instance sizes, generations, or even other families to meet your needs. Spot Advisor makes this easier by publishing likelihood of service interruption by type, size, and region.
Time flexibility
If the workload can wait until the r5.24xl capacity pool becomes available again, consider simply waiting it out. Instance Hibernation is a great tool to leverage in these scenarios because it helps you resume work between interruptions without having to start over or migrate workloads.
Region flexibility
Each Availability Zone in every region has its own capacity pools. With the right combination, you can still achieve savings compared to on-demand instances.
Most of the legwork around finding the lowest-priced capacity pools and spot instances can be done for you using AWS Spot Fleet. Use the Instance Weighting feature to compile a list of instance types/sizes compatible with your applications and give them each a score;
Spot Fleet then delivers the needed resources upon deployment and replaces them when interruptions occur.
Common Questions
How many capacity pools should I use?
There isn’t a perfect answer, but generally it’s recommended you stay between 4 to 21 capacity pools. Your main goal here is to distribute your workload across enough capacity pools to handle the occasional interruption–but not so many that your fleet is constantly exposed to them.
Should I be afraid of Spot Instance interruptions?
You won’t have to be as long as you are prepared for it. Before your instance is interrupted, AWS sends a 2-minute interruption notice. Since January 2018, these notifications can be leveraged as a CloudWatch event to minimize the impact of interruptions significantly. Just check out this AWS walk-through utilizing CloudWatch Events to automatically de-register Spot Instances from an Elastic Load Balancing Application Load Balancer. And don’t forget about Instance Hibernation, which gives you the option to resume workloads that were interrupted.
With a combination of multiple capacity pools and scripts that orchestrate your workloads around interruptions, you can feel much more confident in running on Spot Instances.
Use Cases
Now that you have a solid understanding of how Spot Instances work, you’ve probably put together that most use cases should have the following in common:
- Fault tolerant
- Instance flexible
- Stateless
- Loosely coupled
- Multi-AZ
AWS divides their Spot use cases based on time sensitivity
| Time Sensitive Use Cases | Description |
|---|---|
| Web Services | Experiments |
| APIs | Development |
| Big Data | Testing |
| Grid Computing | One-time Queries |
| Production sequencing | Modal training |
Most of the above use cases could utilize one of the following Spot use strategies:
- Acceleration
Think 1,000 nodes for 1 hour versus 100 nodes for 10 hours. Reducing your workload hours by multiplying your vCPUs ensures faster delivery with no worry of interruptions.
- Diversification
Make interruptions irrelevant by clustering different instance types/families and distributing your workloads among them.
- Hibernation
Resume workloads when resources are available.
Spot instances can be intimidating at first due to their risk of interruptions, but today you’ve learned several ways to mitigate that risk. Now go get those epic savings!
Understanding EC2 Reserved Instances
In the EC2 Pricing Options section, we gave you a quick summary of the benefits and pitfalls of choosing a Reserved instance. Now, let’s look at Reserved Instances (RI) in more detail.
First, let’s tackle a common misconception about RIs. People generally tend to think of a Reserved Instance as one particular instance that you deploy for the duration of the contract term. That is not the case; RIs are simply a 1 or 3 year coupon that applies to any instance usage which matches what you paid for in the reservation (e.g. m5.2xl in us-east-1b running Linux). At the end of the month, any instance usage matching that criteria is billed at the discounted rate.
The price of a Reserved Instance is determined by three main factors: instance attributes, term commitment, and payment method. Here’s a breakdown:
- Instance Attributes
Instance Type, Availability Zone, Tenancy, Platform
- Term Commitment
1 year or 3 years
- Payment Method
Upfront, Partial Upfront, or No Upfront
Deeper savings can be achieved through a combination of longer term commitments and upfront payment. That being said, who knows what their workload patterns will look like in 3 years? In reality, you run the risk of getting stuck with RIs that you no longer need. Sure, you can hawk them off on AWS’s RI Marketplace, but there’s no guarantee they’ll sell–and when they do, it might be for less than your initial contract. That’s money wasted.
Fortunately, you can prevent this by using a little strategy. But before we look at some strategies, let’s talk about the RI Classes that determine which approach to take.
Standard and Convertible Reserved Instances
To complicate pricing even more, there are two Reserved Instance Classes:
Standard RIs and Convertible RIs.
In some ways, these classes are pretty similar. All RIs, regardless of their class and terms, can apply their usage across the Availability Zones of their AWS region. They both can reserve capacity when assigned to a specific Availability Zone. And they both can be shared between multiple accounts when part of a consolidated billing family.
Here’s where they differ:
| Differences | Standard | Convertible |
|---|---|---|
| 1 Year Savings | 40% | 31% |
| 3 Year Savings | 60% | 54% |
| Change Instance Family | No | Yes |
| Change Payment Option | No | Yes |
| Sellable on RI Marketplace | Yes | Not Yet |
| Price Reductions | No | Yes |
So which one’s better? Neither; you’ll likely want to use both for different needs. For the sake of this article, let’s look at Standard RI.
Standard RI
A 1 Year Standard RI with no upfront cost is the most typical scenario for reserved instances; it has the least risk with guaranteed savings against On-Demand.
One possible strategy using this scenario would be to select one or two long-term applications in your infrastructure that run 24⁄7 and migrate them to Reserved Instances that have the capacity to handle mild workload increases. Then evaluate your reservation needs quarterly, running on-demand instances in the interim for any increase in resource needs.
The absolute safest approach would be to transition only a certain percentage of your core workloads to Standard Reserved Instances. (Remember, EC2 pricing options are not all-or-nothing. Use a mix.) Something between 20-45% would still give you significant savings while allowing for future business needs to scale up or down.
Size flexibility is an important and practically useful benefit which should not be underestimated and which was introduced in March 2017. As long as you buy your reservation for a region (vs. an Availability Zone) then your reservation could apply to any reservation of that type but of any size using a normalization model described in this article.
| Instance Size | Normalization Factor |
|---|---|
| nano | 0.25 |
| micro | 0.5 |
| small | 1 |
| medium | 2 |
| large | 4 |
| xlarge | 8 |
| 2xlarge | 16 |
| 4xlarge | 32 |
| 8xlarge | 64 |
| 10xlarge | 80 |
| 16xlarge | 128 |
| 32xlarge | 256 |
A couple of common mistakes to avoid
A reservation subscription does not equate to availability of capacity in a given region when you require to launch an EC2, unless you purchase your reservation for only a specific Availability Zone. There lies a common mistake: If you buy your reservation for a specific AZ, the downside is that your subscription would not only not work for instances launched in any other AZ, but also not work for instances launched of a different size. So you are trading off capacity reservation for flexibility. You must watch your reservation coverage using tools provided in the AWS console to be sure that your usage is as expected.
In environments where the number of running instances vary during the day (peak vs. non-peak hours), it is easy to over-buy reservations if you don’t consider the hourly distribution of usage during the course of a day. The concept is a tricky, so it’s worth reading this blog if you scale your environment during the day.
Auto Scaling your EC2s
Auto Scaling is a powerful tool which automates the sizing of your infrastructure based on your chosen throughput demands (such as increased traffic or workloads). Using Auto Scaling with EC2s ensures stable user experiences without overpaying for unused resources.
Here’s what you’ll need to leverage Auto Scaling:
- An AMI that contains your applications
- Launch Configurations to spin cloned EC2s
- An Auto Scaling Group to maintain your EC2s
- A Load Balancer to distribute incoming traffic within your ASG
Setup Basics
1. Launch Configurations
Launch Configurations are the blueprints needed to spin up additional instances in an Auto Scaling Group. They contain important information such as the AMI, security groups, EBS volumes, user data, and many more specifics for the instances being launched.
2. Auto Scaling Groups
Auto Scaling Groups contain a collection of EC2 instances primed to scale together based on metric thresholds that you have set in CloudWatch. This group can be configured with a minimum size, maximum size, and target capacity. Once the criteria has been met to trigger your CloudWatch alarm, the group scales in an attempt to manage your resource usage and mitigate over or under provisioning. When done correctly, this will greatly increase the efficiency of your total cost of operations and high availability of your application.
While going through the ASG configuration, you will need to select your Network (VPC) and Subnets. The VPC will determine the network space that the ASG will deploy instances in while the subnets will determine which Availability Zone your ASG has the ability to deploy your instances in. We recommend providing at least two different Availability Zones (subnets) for each Auto Scaling Group.
Lastly, you’ll want to attach an Elastic Load Balancer to your Auto Scaling Group.
3. Elastic Load Balancers
There are three Load Balancer types available in AWS: Application Load Balancers, Elastic Load Balancers (now referred to as classic or CLBs) and Network Load Balancers. Load balancers serve as a single point of contact for clients and distributes traffic to maintain application availability.
- Application Load Balancers
Route traffic to specific resource types based on URL path and complex rules.
For example, pointing a specific URL to a specific micro-service.
- Classic Load Balancers
Route traffic between clients and backend servers based on TCP port.
- Network Load Balancers
Maintain a set of static IPs (based on the AZs you attach) and route traffic to a static IP address or Target Group
For the purposes of this article, let’s take a look at a comparison between Classic ELBs and ALBs:
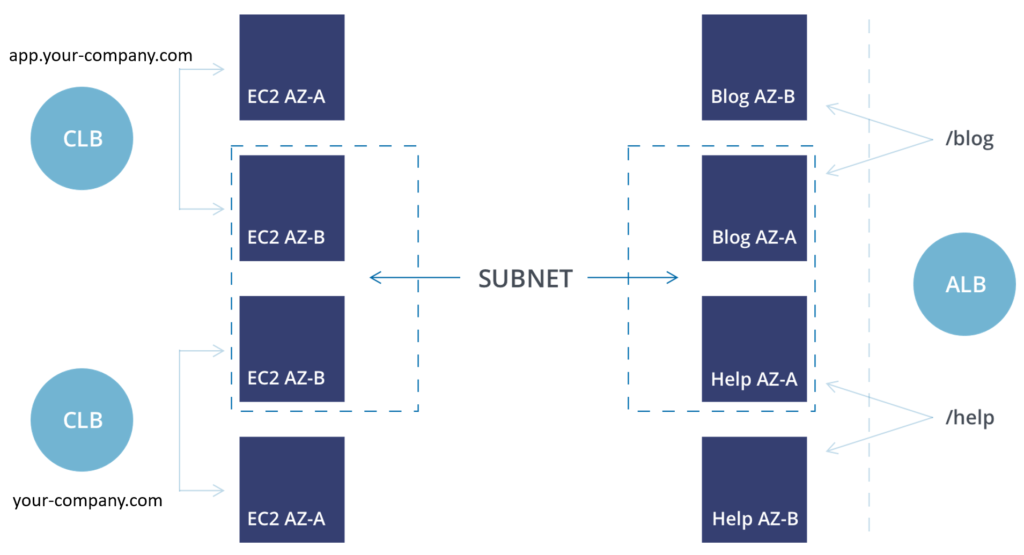
- Elastic Load Balancer (CLB)
Using an Elastic Load Balancer to serve up / will always send traffic to the same backend servers. This means that the backend server is responsible for routing requests based on headers. Without having some web proxy in place (apache, nginx, etc.) a user hitting /billing would get the same results as a user hitting /blog.
- Application Load Balancer
Application Load Balancers can be set to do the proxying for you. Users hitting /billing can be sent to one application target group, while /blog can be sent to a completely different target group. This is extremely helpful in mitigating management of multiple load balancers by simply applying routing rules based on host and or header path.
Feature Comparison
Once you’ve picked your load balancer (most likely an ALB), it’s time to build some policies.
| Feature | ELB | ALB |
|---|---|---|
| Cross-Zone Load Balancing | Manual enablement required | Automatically scales |
| Health Checks | Basic auto detection | Customizable with detailed HTTP error codes (200-399) |
| Cloudwatch | Basic | Added metrics |
| EC2 Classic VPC Support | Yes | No |
| Dynamic Port Mapping | No, fixed only. | Yes, via EC2 Container service |
| Access Logs | Yes | Yes + HTTP/S and Websocket requests |
| Path-Based Routing | No | Yes |
| Deletion Protection | No | Yes |
| Backend Auth | No | Yes |
Auto Scaling Policies
Policies inform how and when your Auto Scaling Group resizes. Step Scaling and Track Scaling are the most commonly used methods, but we’re going to cover them all.
Simple Scaling vs. Step Scaling
Simple Scaling is the classic scaling option AWS first published. It works by listening to a health check on your Auto Scaling Group and provisions more instances when the alarm fires. Once triggered, a cooldown period goes into effect to prevent overcompensation for multiple alarms in a given timeframe.
Unlike Simple Scaling, Step Scaling does not have a cooldown period. These policies evaluate all alarms that fire.
Adjustment Types
The following adjustment types are used in both Simple and Step Scaling policies:
- ChangeInCapacity
Increases or decreases capacity by a set value.
- ExactCapacity
Changes the ASG capacity to the exact value given.
- PercentChangeInCapacity
Increases or decreases capacity of the ASG based on a set % of the whole group.
Target Track Scaling
Target Track Scaling is the newest and simplest way to manage your Auto Scaling policies. When creating the scaling policy, simply choose between creating a standard or custom metric and input a preferred value for it. The scaling policy then creates CloudWatch alarms tailored to maintaining your targeted metric and value. When the alarms fire, it scales back up (or down) to match your target.
Custom Scaling
A good custom metric must encapsulate the state of instance utilization across your entire ASG — otherwise, it scales poorly.

Lawrence Lane


